NeuralNetworkRuntime
提供Neural Network Runtime加速模型推理的相关接口。
@Syscap SystemCapability.Ai.NeuralNetworkRuntime
起始版本:
9
汇总
文件
| 文件名称 | 描述 |
|---|---|
| neural_network_runtime.h | Neural Network Runtime部件接口定义,AI推理框架通过Neural Network Runtime提供的Native接口,完成模型构造与编译,并在加速硬件上执行推理计算。 引用文件:<neural_network_runtime/neural_network_runtime.h> 库:libneural_network_runtime.so |
| neural_network_runtime_type.h | Neural Network Runtime定义的结构体和枚举值。 引用文件:<neural_network_runtime/neural_network_runtime_type.h> 库:libneural_network_runtime.so |
结构体
| 结构体名称 | 描述 |
|---|---|
| OH_NN_UInt32Array | 自定义的32位无符号整型数组。 |
| OH_NN_QuantParam | 量化信息。 |
| OH_NN_Tensor | 张量结构体。 |
| OH_NN_Memory | 内存结构体。 |
类型定义
| 类型定义名称 | 描述 |
|---|---|
| OH_NNModel | Neural Network Runtime的模型句柄。 |
| OH_NNCompilation | Neural Network Runtime的编译器句柄。 |
| OH_NNExecutor | Neural Network Runtime的执行器句柄。 |
| OH_NN_UInt32Array | 自定义的32位无符号整型数组类型。 |
| OH_NN_QuantParam | 量化信息。 |
| OH_NN_Tensor | 张量结构体。 |
| OH_NN_Memory | 内存结构体。 |
枚举
| 枚举名称 | 描述 |
|---|---|
| OH_NN_PerformanceMode { OH_NN_PERFORMANCE_NONE = 0, OH_NN_PERFORMANCE_LOW = 1, OH_NN_PERFORMANCE_MEDIUM = 2, OH_NN_PERFORMANCE_HIGH = 3, OH_NN_PERFORMANCE_EXTREME = 4 } | 硬件的性能模式。 |
| OH_NN_Priority { OH_NN_PRIORITY_NONE = 0, OH_NN_PRIORITY_LOW = 1, OH_NN_PRIORITY_MEDIUM = 2, OH_NN_PRIORITY_HIGH = 3 } | 模型推理任务优先级。 |
| OH_NN_ReturnCode { OH_NN_SUCCESS = 0, OH_NN_FAILED = 1, OH_NN_INVALID_PARAMETER = 2, OH_NN_MEMORY_ERROR = 3, OH_NN_OPERATION_FORBIDDEN = 4, OH_NN_NULL_PTR = 5, OH_NN_INVALID_FILE = 6, OH_NN_UNAVALIDABLE_DEVICE = 7, OH_NN_INVALID_PATH = 8 } | Neural Network Runtime 定义的错误码类型。 |
| OH_NN_FuseType : int8_t { OH_NN_FUSED_NONE = 0, OH_NN_FUSED_RELU = 1, OH_NN_FUSED_RELU6 = 2 } | Neural Network Runtime 融合算子中激活函数的类型。 |
| OH_NN_Format { OH_NN_FORMAT_NONE = 0, OH_NN_FORMAT_NCHW = 1, OH_NN_FORMAT_NHWC = 2 } | 张量数据的排布类型。 |
| OH_NN_DeviceType { OH_NN_OTHERS = 0, OH_NN_CPU = 1, OH_NN_GPU = 2, OH_NN_ACCELERATOR = 3 } | Neural Network Runtime 支持的设备类型。 |
| OH_NN_DataType { OH_NN_UNKNOWN = 0, OH_NN_BOOL = 1, OH_NN_INT8 = 2, OH_NN_INT16 = 3, OH_NN_INT32 = 4, OH_NN_INT64 = 5, OH_NN_UINT8 = 6, OH_NN_UINT16 = 7, OH_NN_UINT32 = 8, OH_NN_UINT64 = 9, OH_NN_FLOAT16 = 10, OH_NN_FLOAT32 = 11, OH_NN_FLOAT64 = 12 } | Neural Network Runtime 支持的数据类型。 |
| OH_NN_OperationType { OH_NN_OPS_ADD = 1, OH_NN_OPS_AVG_POOL = 2, OH_NN_OPS_BATCH_NORM = 3, OH_NN_OPS_BATCH_TO_SPACE_ND = 4, OH_NN_OPS_BIAS_ADD = 5, OH_NN_OPS_CAST = 6, OH_NN_OPS_CONCAT = 7, OH_NN_OPS_CONV2D = 8, OH_NN_OPS_CONV2D_TRANSPOSE = 9, OH_NN_OPS_DEPTHWISE_CONV2D_NATIVE = 10, OH_NN_OPS_DIV = 11, OH_NN_OPS_ELTWISE = 12, OH_NN_OPS_EXPAND_DIMS = 13, OH_NN_OPS_FILL = 14, OH_NN_OPS_FULL_CONNECTION = 15, OH_NN_OPS_GATHER = 16, OH_NN_OPS_HSWISH = 17, OH_NN_OPS_LESS_EQUAL = 18, OH_NN_OPS_MATMUL = 19, OH_NN_OPS_MAXIMUM = 20, OH_NN_OPS_MAX_POOL = 21, OH_NN_OPS_MUL = 22, OH_NN_OPS_ONE_HOT = 23, OH_NN_OPS_PAD = 24, OH_NN_OPS_POW = 25, OH_NN_OPS_SCALE = 26, OH_NN_OPS_SHAPE = 27, OH_NN_OPS_SIGMOID = 28, OH_NN_OPS_SLICE = 29, OH_NN_OPS_SOFTMAX = 30, OH_NN_OPS_SPACE_TO_BATCH_ND = 31, OH_NN_OPS_SPLIT = 32, OH_NN_OPS_SQRT = 33, OH_NN_OPS_SQUARED_DIFFERENCE = 34, OH_NN_OPS_SQUEEZE = 35, OH_NN_OPS_STACK = 36, OH_NN_OPS_STRIDED_SLICE = 37, OH_NN_OPS_SUB = 38, OH_NN_OPS_TANH = 39, OH_NN_OPS_TILE = 40, OH_NN_OPS_TRANSPOSE = 41, OH_NN_OPS_REDUCE_MEAN = 42, OH_NN_OPS_RESIZE_BILINEAR = 43, OH_NN_OPS_RSQRT = 44, OH_NN_OPS_RESHAPE = 45, OH_NN_OPS_PRELU = 46, OH_NN_OPS_RELU = 47, OH_NN_OPS_RELU6 = 48, OH_NN_OPS_LAYER_NORM = 49, OH_NN_OPS_REDUCE_PROD = 50, OH_NN_OPS_REDUCE_ALL = 51, OH_NN_OPS_QUANT_DTYPE_CAST = 52, OH_NN_OPS_TOP_K = 53, OH_NN_OPS_ARG_MAX = 54, OH_NN_OPS_UNSQUEEZE = 55, OH_NN_OPS_GELU = 56 } | Neural Network Runtime 支持算子的类型。 |
| OH_NN_TensorType { OH_NN_TENSOR = 0, OH_NN_ADD_ACTIVATIONTYPE = 1, OH_NN_AVG_POOL_KERNEL_SIZE = 2, OH_NN_AVG_POOL_STRIDE = 3, OH_NN_AVG_POOL_PAD_MODE = 4, OH_NN_AVG_POOL_PAD = 5, OH_NN_AVG_POOL_ACTIVATION_TYPE = 6, OH_NN_BATCH_NORM_EPSILON = 7, OH_NN_BATCH_TO_SPACE_ND_BLOCKSIZE = 8, OH_NN_BATCH_TO_SPACE_ND_CROPS = 9, OH_NN_CONCAT_AXIS = 10, OH_NN_CONV2D_STRIDES = 11, OH_NN_CONV2D_PAD = 12,OH_NN_CONV2D_DILATION = 13, OH_NN_CONV2D_PAD_MODE = 14, OH_NN_CONV2D_ACTIVATION_TYPE = 15, OH_NN_CONV2D_GROUP = 16, OH_NN_CONV2D_TRANSPOSE_STRIDES = 17, OH_NN_CONV2D_TRANSPOSE_PAD = 18, OH_NN_CONV2D_TRANSPOSE_DILATION = 19, OH_NN_CONV2D_TRANSPOSE_OUTPUT_PADDINGS = 20, OH_NN_CONV2D_TRANSPOSE_PAD_MODE = 21, OH_NN_CONV2D_TRANSPOSE_ACTIVATION_TYPE = 22, OH_NN_CONV2D_TRANSPOSE_GROUP = 23, OH_NN_DEPTHWISE_CONV2D_NATIVE_STRIDES = 24, OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD = 25, OH_NN_DEPTHWISE_CONV2D_NATIVE_DILATION = 26, OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD_MODE = 27, OH_NN_DEPTHWISE_CONV2D_NATIVE_ACTIVATION_TYPE = 28, OH_NN_DIV_ACTIVATIONTYPE = 29, OH_NN_ELTWISE_MODE = 30, OH_NN_FULL_CONNECTION_AXIS = 31, OH_NN_FULL_CONNECTION_ACTIVATIONTYPE = 32, OH_NN_MATMUL_TRANSPOSE_A = 33, OH_NN_MATMUL_TRANSPOSE_B = 34, OH_NN_MATMUL_ACTIVATION_TYPE = 35, OH_NN_MAX_POOL_KERNEL_SIZE = 36, OH_NN_MAX_POOL_STRIDE = 37, OH_NN_MAX_POOL_PAD_MODE = 38, OH_NN_MAX_POOL_PAD = 39, OH_NN_MAX_POOL_ACTIVATION_TYPE = 40, OH_NN_MUL_ACTIVATION_TYPE = 41, OH_NN_ONE_HOT_AXIS = 42, OH_NN_PAD_CONSTANT_VALUE = 43, OH_NN_SCALE_ACTIVATIONTYPE = 44, OH_NN_SCALE_AXIS = 45, OH_NN_SOFTMAX_AXIS = 46, OH_NN_SPACE_TO_BATCH_ND_BLOCK_SHAPE = 47, OH_NN_SPACE_TO_BATCH_ND_PADDINGS = 48, OH_NN_SPLIT_AXIS = 49, OH_NN_SPLIT_OUTPUT_NUM = 50, OH_NN_SPLIT_SIZE_SPLITS = 51, OH_NN_SQUEEZE_AXIS = 52, OH_NN_STACK_AXIS = 53, OH_NN_STRIDED_SLICE_BEGIN_MASK = 54, OH_NN_STRIDED_SLICE_END_MASK = 55, OH_NN_STRIDED_SLICE_ELLIPSIS_MASK = 56, OH_NN_STRIDED_SLICE_NEW_AXIS_MASK = 57, OH_NN_STRIDED_SLICE_SHRINK_AXIS_MASK = 58, OH_NN_SUB_ACTIVATIONTYPE = 59, OH_NN_REDUCE_MEAN_KEEP_DIMS = 60, OH_NN_RESIZE_BILINEAR_NEW_HEIGHT = 61, OH_NN_RESIZE_BILINEAR_NEW_WIDTH = 62, OH_NN_RESIZE_BILINEAR_PRESERVE_ASPECT_RATIO = 63, OH_NN_RESIZE_BILINEAR_COORDINATE_TRANSFORM_MODE = 64, OH_NN_RESIZE_BILINEAR_EXCLUDE_OUTSIDE = 65, OH_NN_LAYER_NORM_BEGIN_NORM_AXIS = 66, OH_NN_LAYER_NORM_EPSILON = 67, OH_NN_LAYER_NORM_BEGIN_PARAM_AXIS = 68, OH_NN_LAYER_NORM_ELEMENTWISE_AFFINE = 69, OH_NN_REDUCE_PROD_KEEP_DIMS = 70, OH_NN_REDUCE_ALL_KEEP_DIMS = 71, OH_NN_QUANT_DTYPE_CAST_SRC_T = 72, OH_NN_QUANT_DTYPE_CAST_DST_T = 73, OH_NN_TOP_K_SORTED = 74, OH_NN_ARG_MAX_AXIS = 75, OH_NN_ARG_MAX_KEEPDIMS = 76, OH_NN_UNSQUEEZE_AXIS = 77 } | 张量的类型。 |
函数
| 函数 名称 | 描述 |
|---|---|
| OH_NNModel_Construct (void) | 创建OH_NNModel类型的模型实例,搭配OH_NNModel模块提供的其他接口,完成模型实例的构造。 |
| OH_NNModel_AddTensor (OH_NNModel *model, const OH_NN_Tensor *tensor) | 向模型实例中添加张量。 |
| OH_NNModel_SetTensorData (OH_NNModel *model, uint32_t index, const void *dataBuffer, size_t length) | 设置张量的数值。 |
| OH_NNModel_AddOperation (OH_NNModel *model, OH_NN_OperationType op, const OH_NN_UInt32Array *paramIndices, const OH_NN_UInt32Array *inputIndices, const OH_NN_UInt32Array *outputIndices) | 向模型实例中添加算子。 |
| OH_NNModel_SpecifyInputsAndOutputs (OH_NNModel *model, const OH_NN_UInt32Array *inputIndices, const OH_NN_UInt32Array *outputIndices) | 指定模型的输入输出。 |
| OH_NNModel_Finish (OH_NNModel *model) | 完成模型构图。 |
| OH_NNModel_Destroy (OH_NNModel **model) | 释放模型实例。 |
| OH_NNModel_GetAvailableOperations (OH_NNModel *model, size_t deviceID, const bool **isSupported, uint32_t *opCount) | 查询硬件对模型内所有算子的支持情况,通过布尔值序列指示支持情况。 |
| OH_NNCompilation_Construct (const OH_NNModel *model) | 创建OH_NNCompilation类型的编译实例。 |
| OH_NNCompilation_SetDevice (OH_NNCompilation *compilation, size_t deviceID) | 指定模型编译和计算的硬件。 |
| OH_NNCompilation_SetCache (OH_NNCompilation *compilation, const char *cachePath, uint32_t version) | 设置编译后的模型缓存路径和缓存版本。 |
| OH_NNCompilation_SetPerformanceMode (OH_NNCompilation *compilation, OH_NN_PerformanceMode performanceMode) | 设置硬件的性能模式。 |
| OH_NNCompilation_SetPriority (OH_NNCompilation *compilation, OH_NN_Priority priority) | 设置模型计算的优先级。 |
| OH_NNCompilation_EnableFloat16 (OH_NNCompilation *compilation, bool enableFloat16) | 是否以float16的浮点数精度计算。 |
| OH_NNCompilation_Build (OH_NNCompilation *compilation) | 进行模型编译。 |
| OH_NNCompilation_Destroy (OH_NNCompilation **compilation) | 释放Compilation对象。 |
| OH_NNExecutor_Construct (OH_NNCompilation *compilation) | 创建OH_NNExecutor类型的执行器实例。 |
| OH_NNExecutor_SetInput (OH_NNExecutor *executor, uint32_t inputIndex, const OH_NN_Tensor *tensor, const void *dataBuffer, size_t length) | 设置模型单个输入的数据。 |
| OH_NNExecutor_SetOutput (OH_NNExecutor *executor, uint32_t outputIndex, void *dataBuffer, size_t length) | 设置模型单个输出的缓冲区。 |
| OH_NNExecutor_GetOutputShape (OH_NNExecutor *executor, uint32_t outputIndex, int32_t **shape, uint32_t *shapeLength) | 获取输出张量的维度信息。 |
| OH_NNExecutor_Run (OH_NNExecutor *executor) | 执行推理。 |
| OH_NNExecutor_AllocateInputMemory (OH_NNExecutor *executor, uint32_t inputIndex, size_t length) | 在硬件上为单个输入申请共享内存。 |
| OH_NNExecutor_AllocateOutputMemory (OH_NNExecutor *executor, uint32_t outputIndex, size_t length) | 在硬件上为单个输出申请共享内存。 |
| OH_NNExecutor_DestroyInputMemory (OH_NNExecutor *executor, uint32_t inputIndex, OH_NN_Memory **memory) | 释放OH_NN_Memory实例指向的输入内存。 |
| OH_NNExecutor_DestroyOutputMemory (OH_NNExecutor *executor, uint32_t outputIndex, OH_NN_Memory **memory) | 释放OH_NN_Memory实例指向的输出内存。 |
| OH_NNExecutor_SetInputWithMemory (OH_NNExecutor *executor, uint32_t inputIndex, const OH_NN_Tensor *tensor, const OH_NN_Memory *memory) | 将OH_NN_Memory实例指向的硬件共享内存,指定为单个输入使用的共享内存。 |
| OH_NNExecutor_SetOutputWithMemory (OH_NNExecutor *executor, uint32_t outputIndex, const OH_NN_Memory *memory) | 将OH_NN_Memory实例指向的硬件共享内存,指定为单个输出使用的共享内存。 |
| OH_NNExecutor_Destroy (OH_NNExecutor **executor) | 销毁执行器实例,释放执行器占用的内存。 |
| OH_NNDevice_GetAllDevicesID (const size_t **allDevicesID, uint32_t *deviceCount) | 获取对接到 Neural Network Runtime 的硬件ID。 |
| OH_NNDevice_GetName (size_t deviceID, const char **name) | 获取指定硬件的类型信息。 |
| OH_NNDevice_GetType (size_t deviceID, OH_NN_DeviceType *deviceType) | 获取指定硬件的类别信息。 |
类型定义说明
OH_NN_Memory
typedef struct OH_NN_Memory OH_NN_Memory
描述:
内存结构体。
OH_NN_QuantParam
typedef struct OH_NN_QuantParam OH_NN_QuantParam
描述:
量化信息。
在量化的场景中,32位浮点型数据根据以下公式量化为定点数据:
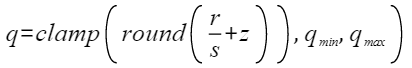
其中s和z是量化参数,在OH_NN_QuanParam中通过scale和zeroPoint保存,r是浮点数,q是量化后的结果,q_min是量化后下界,q_max是量化后的上界,计算方式如下:
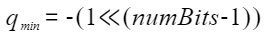
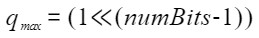
clamp函数定义如下:
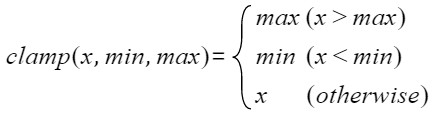
OH_NN_Tensor
typedef struct OH_NN_Tensor OH_NN_Tensor
描述:
张量结构体。
通常用于构造模型图中的数据节点和算子参数,在构造张量时需要明确数据类型、维数、维度信息和量化信息。
OH_NN_UInt32Array
typedef struct OH_NN_UInt32Array OH_NN_UInt32Array
描述:
自定义的32位无符号整型数组类型。
OH_NNCompilation
typedef struct OH_NNCompilation OH_NNCompilation
描述:
Neural Network Runtime的编译器句柄。
OH_NNExecutor
typedef struct OH_NNExecutor OH_NNExecutor
描述:
Neural Network Runtime的执行器句柄。
OH_NNModel
typedef struct OH_NNModel OH_NNModel
描述:
Neural Network Runtime的模型句柄。
枚举类型说明
OH_NN_DataType
enum OH_NN_DataType
描述:
Neural Network Runtime支持的数据类型。
| 枚举值 | 描述 |
|---|---|
| OH_NN_UNKNOWN | 张量数据类型未知。 |
| OH_NN_BOOL | 张量数据类型为bool。 |
| OH_NN_INT8 | 张量数据类型为int8。 |
| OH_NN_INT16 | 张量数据类型为int16。 |
| OH_NN_INT32 | 张量数据类型为int32。 |
| OH_NN_INT64 | 张量数据类型为int64。 |
| OH_NN_UINT8 | 张量数据类型为uint8。 |
| OH_NN_UINT16 | 张量数据类型为uint16。 |
| OH_NN_UINT32 | 张量数据类型为uint32。 |
| OH_NN_UINT64 | 张量数据类型为uint64。 |
| OH_NN_FLOAT16 | 张量数据类型为float16。 |
| OH_NN_FLOAT32 | 张量数据类型为float32。 |
| OH_NN_FLOAT64 | 张量数据类型为float64。 |
OH_NN_DeviceType
enum OH_NN_DeviceType
描述:
Neural Network Runtime支持的设备类型。
| 枚举值 | 描述 |
|---|---|
| OH_NN_OTHERS | 不属于CPU、GPU、专用加速器的设备。 |
| OH_NN_CPU | CPU设备。 |
| OH_NN_GPU | GPU设备。 |
| OH_NN_ACCELERATOR | 专用硬件加速器。 |
OH_NN_Format
enum OH_NN_Format
描述:
张量数据的排布类型。
| 枚举值 | 描述 |
|---|---|
| OH_NN_FORMAT_NONE | 当张量没有特定的排布类型(如标量或矢量)时,使用本枚举值。 |
| OH_NN_FORMAT_NCHW | 当张量按照NCHW的格式排布数据时,使用本枚举值。 |
| OH_NN_FORMAT_NHWC | 当张量按照NHWC的格式排布数据时,使用本枚举值。 |
OH_NN_FuseType
enum OH_NN_FuseType : int8_t
描述:
Neural Network Runtime融合算子中激活函数的类型。
| 枚举值 | 描述 |
|---|---|
| OH_NN_FUSED_NONE | 未指定融合激活函数。 |
| OH_NN_FUSED_RELU | 融合relu激活函数。 |
| OH_NN_FUSED_RELU6 | 融合relu6激活函数。 |
OH_NN_OperationType
enum OH_NN_OperationType
描述:
Neural Network Runtime支持算子的类型。
| 枚举值 | 描述 |
|---|---|
| OH_NN_OPS_ADD | 返回两个输入张量对应元素相加的和的张量。 输入: - input1,第一个输入的张量,数据类型要求为布尔值或者数字。 - input2,第二个输入的张量,数据类型和形状需要和第一个输入保持一致。 参数: - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,input1和input2的和,数据形状与输入broadcast之后一样,数据类型与较高精度的输入精度一致 |
| OH_NN_OPS_AVG_POOL | 在输入张量上应用2D平均池化,仅支持NHWC格式的张量。支持int8量化输入。 如果输入中含有padMode参数: 输入: - input,一个张量。 参数: - kernelSize,用来取平均值的kernel大小,是一个长度为2的int数组[kernel_height,kernel_weight], 第一个数表示kernel高度,第二个数表示kernel宽度。 - strides,kernel移动的距离,是一个长度为2的int数组[stride_height,stride_weight], 第一个数表示高度上的移动步幅,第二个数表示宽度上的移动步幅。 - padMode,填充模式,int类型的可选值,0表示same,1表示valid,并且以最近邻的值填充。 same,输出的高度和宽度与input相同,填充总数将在水平和垂直方向计算,并在可能的情况下均匀分布到顶部 和底部、左侧和右侧。否则,最后一个额外的填充将从底部和右侧完成。 valid,输出的可能最大高度和宽度将在不填充的情况下返回。额外的像素将被丢弃。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 如果输入中含有padList参数: 输入: - input,一个张量。 参数: - kernelSize,用来取平均值的kernel大小,是一个长度为2的int数组[kernel_height,kernel_weight], 第一个数表示kernel高度,第二个数表示kernel宽度。 - strides,kernel移动的距离,是一个长度为2的int数组[stride_height,stride_weight], 第一个数表示高度上的移动步幅,第二个数表示宽度上的移动步幅。 - padList,input周围的填充,是一个长度为4的int数组[top,bottom,left,right],并且以最近邻的值填充。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,对input进行平均池化后的结果。 |
| OH_NN_OPS_BATCH_NORM | 对一个张量进行batch normalization,对张量元素进行缩放和位移,缓解一批数据中潜在的covariate shift。 输入: - input,一个n维的张量,要求形状为[N,...,C],即第n维是通道数(channel)。 - scale,缩放因子的1D张量,用于缩放归一化的第一个张量。 - offset,用于偏移的1D张量,以移动到归一化的第一个张量。 - mean,总体均值的一维张量,仅用于推理;对于训练,必须为空。 - variance,用于总体方差的一维张量。仅用于推理;对于训练,必须为空。 参数: - epsilon,数值稳定性的小附加值。 输出: - output,n维输出张量,形状和数据类型与input一致。 |
| OH_NN_OPS_BATCH_TO_SPACE_ND | 将一个四维张量的batch维度按block_shape切分成小块,并将这些小块拼接到空间维度。 参数: - input,输入张量,维将被切分,拼接回空间维度。 输出: - blockSize,一个长度为2的数组[height_block,weight_block],指定切分到空间维度上的block大小。 - crops,一个shape为(2,2)的二维数组[[crop0_start,crop0_end],[crop1_start,crop1_end]], 表示在output的空间维度上截掉部分元素。 输出: - output,假设input的形状为(n,h,w,c),output的形状为(n',h',w',c'): n' = n / (block_shape[0] * block_shape[1]) h' = h * block_shape[0] - crops[0][0] - crops[0][1] w' = w * block_shape[1] - crops[1][0] - crops[1][1] c'= c |
| OH_NN_OPS_BIAS_ADD | 对给出的输入张量上的各个维度方向上的数据进行偏置。 输入: - input,输入张量,可为2-5维度。 - bias,参数对应输入维度数量的偏移值。 输出: - output,根据input中每个维度方向偏移后的结果。 |
| OH_NN_OPS_CAST | 对输入张量中的数据类型进行转换。 输入: - input,输入张量。 - type,转换后的数据类型。 输出: - output,转换后的张量。 |
| OH_NN_OPS_CONCAT | 在指定维度上连接张量。 输入: - input:N个输入张量。 参数: - axis,指定张量连接的维度。 输出: - output,输出N个张量沿axis连接的结果。 |
| OH_NN_OPS_CONV2D | 二维卷积层。 如果输入中含有padMode参数: 输入: - input,输入张量。 - weight,卷积的权重,要求weight排布为[outChannel,kernelHeight,kernelWidth,inChannel/group], inChannel必须要能整除group。 - bias,卷积的偏置,是长度为[outChannel]的数组。在量化场景下,bias 参数不需要量化参数,其量化 版本要求输入 OH_NN_INT32 类型数据,实际量化参数由 input 和 weight 共同决定。 参数: - stride,卷积核在height和weight上的步幅,是一个长度为2的int数组[strideHeight,strideWidth]。 - dilation,表示扩张卷积在height和weight上的扩张率,是一个长度为2的int数组[dilationHeight,dilationWidth], 值必须大于或等于1,并且不能超过input的height和width。 - padMode,input的填充模式,支持same和valid,int类型,0表示same,1表示valid。 same,输出的高度和宽度与input相同,填充总数将在水平和垂直方向计算,并在可能的情况下均匀分布到顶部和底部、左侧 和右侧。否则,最后一个额外的填充将从底部和右侧完成。 Valid,输出的可能最大高度和宽度将在不填充的情况下返回。额外的像素将被丢弃。 - group,将input按in_channel分组,int类型。group等于1,这是常规卷积;group大于1且小于或等于in_channel,这是分组卷积。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 如果输入中含有padList参数: 输入: - input,输入张量。 - weight,卷积的权重,要求weight排布为[outChannel,kernelHeight,kernelWidth,inChannel/group], inChannel必须要能整除group。 - bias,卷积的偏置,是长度为[outChannel]的数组。在量化场景下,bias 参数不需要量化参数,其量化 版本要求输入 OH_NN_INT32 类型数据,实际量化参数由 input 和 weight 共同决定。 参数: - stride,卷积核在height和weight上的步幅,是一个长度为2的int数组[strideHeight,strideWidth]。 - dilation,表示扩张卷积在height和weight上的扩张率,是一个长度为2的int数组[dilationHeight,dilationWidth]。 值必须大于或等于1,并且不能超过input的height和width。 - padList,input周围的填充,是一个长度为4的int数组[top,bottom,left,right]。 - group,将input按in_channel分组,int类型。 group等于1,这是常规卷积。 group等于in_channel,这是depthwiseConv2d,此时group==in_channel==out_channel。 group大于1且小于in_channel,这是分组卷积,out_channel==group。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,卷积计算结果。 |
| OH_NN_OPS_CONV2D_TRANSPOSE | 二维卷积转置。 如果输入中含有padMode参数: 输入: - input,输入张量。 - weight,卷积的权重,要求weight排布为[outChannel,kernelHeight,kernelWidth,inChannel/group], inChannel必须要能整除group。 - bias,卷积的偏置,是长度为[outChannel]的数组。在量化场景下,bias参数不需要量化参数,其量化 版本要求输入OH_NN_INT32类型数据,实际量化参数由input和weight共同决定。 - stride,卷积核在height和weight上的步幅,是一个长度为2的int数组[strideHeight,strideWidth]。 参数: - dilation,表示扩张卷积在height和weight上的扩张率,是一个长度为2的int数组[dilationHeight,dilationWidth]。 值必须大于或等于1,并且不能超过input的height和width。 - padMode,input的填充模式,支持same和valid,int类型,0表示same,1表示valid。 same,输出的高度和宽度与input相同,填充总数将在水平和垂直方向计算,并在可能的情况下均匀分布到顶部和底部、左侧 和右侧。否则,最后一个额外的填充将从底部和右侧完成。 Valid,输出的可能最大高度和宽度将在不填充的情况下返回。额外的像素将被丢弃。 - group,将input按in_channel分组,int类型。group等于1,这是常规卷积;group大于1且小于或等于in_channel,这是分组卷积。 - outputPads,一个整数或元组/2 个整数的列表,指定沿输出张量的高度和宽度的填充量。可以是单个整数,用于为所 有空间维度指定相同的值。沿给定维度的输出填充量必须小于沿同一维度的步幅。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 如果输入中含有padList参数: 输入: - input,输入张量。 - weight,卷积的权重,要求weight排布为[outChannel,kernelHeight,kernelWidth,inChannel/group], inChannel必须要能整除group。 - bias,卷积的偏置,是长度为[outChannel]的数组。在量化场景下,bias 参数不需要量化参数,其量化 版本要求输入 OH_NN_INT32 类型数据,实际量化参数由 input 和 weight 共同决定。 参数: - stride,卷积核在height和weight上的步幅,是一个长度为2的int数组[strideHeight,strideWidth]。 - dilation,表示扩张卷积在height和weight上的扩张率,是一个长度为2的int数组[dilationHeight,dilationWidth]。 值必须大于或等于1,并且不能超过input的height和width。 - padList,input周围的填充,是一个长度为4的int数组[top,bottom,left,right]。 - group,将input按in_channel分组,int类型。group等于1,这是常规卷积;group大于1且小于或等于in_channel,这是分组卷积。 - outputPads,一个整数或元组/2 个整数的列表,指定沿输出张量的高度和宽度的填充量。可以是单个整数,用于为所 有空间维度指定相同的值。沿给定维度的输出填充量必须小于沿同一维度的步幅。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,卷积转置后的计算结果。 |
| OH_NN_OPS_DEPTHWISE_CONV2D_NATIVE | 二维深度可分离卷积。 如果输入中含有padMode参数: 输入: - input,输入张量。 - weight,卷积的权重,要求weight排布为[outChannel,kernelHeight,kernelWidth,1],outChannel = channelMultiplier * inChannel。 - bias,卷积的偏置,是长度为[outChannel]的数组。在量化场景下,bias 参数不需要量化参数,其量化 版本要求输入 OH_NN_INT32 类型数据,实际量化参数由 input 和 weight 共同决定。 参数: - stride,卷积核在height和weight上的步幅,是一个长度为2的int数组[strideHeight,strideWidth]。 - dilation,表示扩张卷积在height和weight上的扩张率,是一个长度为2的int数组[dilationHeight,dilationWidth]。 值必须大于或等于1,并且不能超过input的height和width。 - padMode,input的填充模式,支持same和valid,int类型,0表示same,1表示valid same,输出的高度和宽度与input相同,填充总数将在水平和垂直方向计算,并在可能的情况下均匀分布到顶部和底部、左侧 和右侧。否则,最后一个额外的填充将从底部和右侧完成 Valid,输出的可能最大高度和宽度将在不填充的情况下返回。额外的像素将被丢弃 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 如果输入中含有padList 参数: 输入: - input,输入张量。 - weight,卷积的权重,要求weight排布为[outChannel,kernelHeight,kernelWidth,1],outChannel = channelMultiplier * inChannel。 - bias,卷积的偏置,是长度为[outChannel]的数组。在量化场景下,bias参数不需要量化参数,其量化 版本要求输入 OH_NN_INT32 类型数据,实际量化参数由 input和weight共同决定。 参数: - stride,卷积核在height和weight上的步幅,是一个长度为2的int数组[strideHeight,strideWidth]。 - dilation,表示扩张卷积在height和weight上的扩张率,是一个长度为2的int数组[dilationHeight,dilationWidth]。 值必须大于或等于1,并且不能超过input的height和width。 - padList,input周围的填充,是一个长度为4的int数组[top,bottom,left,right]。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,卷积计算的结果。 |
| OH_NN_OPS_DIV | 对输入的两个标量或张量做除法。 输入: - input1,第一个输入是标量或布尔值或数据类型为数字或布尔值的张量。 - input2,数据类型根据input1的类型,要求有所不同: 当第一个输入是张量时,第二个输入可以是实数或布尔值或数据类型为实数/布尔值的张量。 当第一个输入是实数或布尔值时,第二个输入必须是数据类型为实数/布尔值的张量。 参数: - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,input1和input2相除的结果。 |
| OH_NN_OPS_ELTWISE | 设置参数对输入进行product(点乘)、sum(相加减)或max(取大值)。 输入: - input1,第一个输入张量。 - input2,第二个输入张量。 参数: - mode,枚举,选择操作方式。 输出: - output,计算后的结果,output和input1拥有相同的数据类型和形状。 |
| OH_NN_OPS_EXPAND_DIMS | 在给定维度上为张量添加一个额外的维度。 输入: - input,输入张量。 - axis,需要添加的维度的index,int32_t类型,值必须在[-dim-1,dim],且只允许常量值。 输出: - output,维度拓展后的张量。 |
| OH_NN_OPS_FILL | 根据指定的形状,创建由一个标量填充的张量。 输入: - value,填充的标量。 - shape,指定创建张量的形状。 输出: - output,生成的张量,和value具有相同的数据类型,张量形状由shape参数指定。 |
| OH_NN_OPS_FULL_CONNECTION | 全连接,整个输入作为feature map,进行特征提取。 输入: - input,全连接的输入张量。 - weight,全连接的权重张量。 - bias,全连接的偏置,在量化场景下,bias参数不需要量化参数,其量化版本要求输入OH_NN_INT32 类型数据,实际量化参数由input和weight共同决定。 参数: - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,输出运算后的张量。 如果输入中含有axis参数: 输入: - input,全连接的输入张量。 - weight,全连接的权重张量。 - bias,全连接的偏置,在量化场景下,bias参数不需要量化参数,其量化版本要求输入 OH_NN_INT32 类型数据,实际量化参数由input和weight共同决定。 参数: - axis,input做全连接的轴,从指定轴axis开始,将axis和axis后面的轴展开成一维去做全连接 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,输出运算后的张量。 |
| OH_NN_OPS_GATHER | 根据指定的索引和轴返回输入张量的切片。 输入: - input,输入待切片的张量。 - inputIndices,指定input在axis上的索引,是一个int类型的数组,值必须在[0,input.shape[axis])范围内 - axis,input被切片的轴,int32_t类型的数组,数组长度为1。 输出: - output,输出切片后的张量。 |
| OH_NN_OPS_HSWISH | 计算输入的Hswish激活值。 输入: - input,一个n维输入张量。 输出: - output,n维Hswish激活值,数据类型和shape和input一致。 |
| OH_NN_OPS_LESS_EQUAL | 对input1和input2,计算每对元素的input1[i]<=input2[i]的结果,i是输入张量中每个元素的索引。 输入: - input1,可以是实数、布尔值或数据类型是实数/NN_BOOL的张量。 - input2,如果input1是张量,input2可以是实数、布尔值,否则只能是张量,其数据类型是实数或NN_BOOL。 输出: - 张量,数据类型为NN_BOOL的张量,使用量化模型时,output的量化参数不可省略,但量化参数的数值不会对输入结果产生影响。 |
| OH_NN_OPS_MATMUL | 计算input1和input2的内积。 输入: - input1,n维输入张量。 - input2,n维输入张量。 参数: - TransposeX,布尔值,是否对input1进行转置。 - TransposeY,布尔值,是否对input2进行转置。 输出: - output,计算得到内积,当type!=NN_UNKNOWN时,output数据类型由type决定;当type==NN_UNKNOWN时, output的数据类型取决于input1和input2进行计算时转化的数据类型。 |
| OH_NN_OPS_MAXIMUM | 计算input1和input2对应元素最大值,input1和input2的输入遵守隐式类型转换规则,使数据类型一致。输入必须是两个张量或一个张量和一个标量。当输入是两个张量时,它们的数据类型不能同时为NN_BOOL。它们的形状支持broadcast成相同的大小。当输入是一个张量和一个标量时,标量只能是一个常数。 输入: - input1,n维输入张量,实数或NN_BOOL类型。 - input2,n维输入张量,实数或NN_BOOL类型。 输出: - output,n维输出张量,output的shape和数据类型和两个输入张量中精度或者位数高的相同。 |
| OH_NN_OPS_MAX_POOL | 在输入张量上应用2D最大值池化。 如果输入中含有padMode参数: 输入: - input,一个张量。 参数: - kernelSize,用来取最大值的kernel大小,是一个长度为2的int数组[kernel_height,kernel_weight], 第一个数表示kernel高度,第二个数表示kernel宽度。 - strides,kernel移动的距离,是一个长度为2的int数组[stride_height,stride_weight], 第一个数表示高度上的移动步幅,第二个数表示宽度上的移动步幅。 - padMode,填充模式,int类型的可选值,0表示same,1表示valid,并且以最近邻的值填充。 same,输出的高度和宽度与input相同,填充总数将在水平和垂直方向计算,并在可能的情况下均匀分布到顶部 和底部、左侧和右侧。否则,最后一个额外的填充将从底部和右侧完成。 valid,输出的可能最大高度和宽度将在不填充的情况下返回。额外的像素将被丢弃。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 如果输入中含有padList参数: 输入: - input,一个张量。 参数: - kernelSize,用来取最大值的kernel大小,是一个长度为2的int数组[kernel_height,kernel_weight], 第一个数表示kernel高度,第二个数表示kernel宽度。 - strides,kernel移动的距离,是一个长度为2的int数组[stride_height,stride_weight], 第一个数表示高度上的移动步幅,第二个数表示宽度上的移动步幅。 - padList,input周围的填充,是一个长度为4的int数组[top,bottom,left,right],并且以最近邻的值填充。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,对input最大值池化后的张量。 |
| OH_NN_OPS_MUL | 将input1和input2相同的位置的元素相乘得到output。如果input1和input2类型shape不同,要求input1和input2可以通过broadcast扩充成相同的shape进行相乘。 输入: - input1,一个n维张量。 - input2,一个n维张量。 参数: - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,input1和input2每个元素的乘积。 |
| OH_NN_OPS_ONE_HOT | 根据indices指定的位置,生成一个由one-hot向量构成的张量。每个onehot向量中的有效值由on_value决定,其他位置由off_value决定。 输入: - indices,n维张量。indices中每个元素决定每个one-hot向量,on_value的位置 - depth,一个整型标量,决定one-hot向量的深度。要求depth>0。 - on_value,一个标量,指定one-hot向量中的有效值。 - off_value,一个标量,指定one-hot向量中除有效位以外,其他位置的值。 参数: - axis,一个整型标量,指定插入one-hot的维度。 indices的形状是[N,C],depth的值是D,当axis=0时,output形状为[D,N,C], indices的形状是[N,C],depth的值是D,当axis=-1时,output形状为[N,C,D], indices的形状是[N,C],depth的值是D,当axis=1时,output形状为[N,D,C]。 输出: - output,如果indices时n维张量,则output是(n+1)维张量。output的形状由indices和axis共同决定。 |
| OH_NN_OPS_PAD | 在input1指定维度的数据前后,添加指定数值进行增广。 输入: - input,一个n维张量,要求input1的排布为[BatchSize,…]。 - paddings,一个二维张量,指定每一维度增补的长度,shape为[n,2]。paddings[i][0]表示第i维上,需要在input前增补的数量; paddings[i][1]表示第i维上,需要在inputX后增补的数量。 参数: - padValues,一个常数,数据类型和input一致,指定Pad操作补全的数值。 输出: - output,一个n维张量,维数和数据类型和input保持一致。shape由input和paddings共同决定 output.shape[i] = input.shape[i] + paddings[i][0]+paddings[i][1]。 |
| OH_NN_OPS_POW | 求input的y次幂,输入必须是两个张量或一个张量和一个标量。当输入是两个张量时,它们的数据类型不能同时为NN_BOOL, 且要求两个张量的shape相同。当输入是一个张量和一个标量时,标量只能是一个常数。 输入: - input,实数、bool值或张量,张量的数据类型为实数/NN_BOOL。 - y,实数、bool值或张量,张量的数据类型为实数/NN_BOOL。 输出: - output,形状由input和y通过broadcast后的形状决定。 |
| OH_NN_OPS_SCALE | 给定一个张量,计算其缩放后的值。 输入: - input,一个n维张量。 - scale,缩放张量。 - bias,偏置张量。 参数: - axis,指定缩放的维度。 - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,scale的计算结果,一个n维张量,类型和input一致,shape由axis决定。 |
| OH_NN_OPS_SHAPE | 输入一个张量,计算其shape。 输入: - input,一个n维张量。 输出: - output,输出张量的维度,一个整型数组。 |
| OH_NN_OPS_SIGMOID | 给定一个张量,计算其sigmoid结果。 输入: - input,一个n维张量。 输出: - output,sigmoid的计算结果,一个n维张量,类型和shape和input一致。 |
| OH_NN_OPS_SLICE | 在输入张量的各个维度,以begin为起点,截取size长度的切片。 输入: - input,n维输入张量。 - begin,一组不小于0的整数,指定每个维度上的起始切分点。 - size,一组不小于1的整数,指定每个维度上切片的长度。假设某一维度i,1<=size[i]<=input.shape[i]-begin[i]。 输出: - output,切片得到的n维张量,其TensorType和input一致,shape和size相同。 |
| OH_NN_OPS_SOFTMAX | 给定一个张量,计算其softmax结果。 输入: - input,n维输入张量。 参数: - axis,int64类型,指定计算softmax的维度。整数取值范围为[-n,n)。 输出: - output,softmax的计算结果,一个n维张量,类型和shape和input一致。 |
| OH_NN_OPS_SPACE_TO_BATCH_ND | 将四维张量在空间维度上进行切分成blockShape[0] * blockShape[1]个小块,然后在batch维度上拼接这些小块。 输入: - input,一个四维张量 参数: - blockShape,一对整数,每个整数不小于1。 - paddings,一对数组,每个数组由两个整数组成。组成paddings的4个整数都不小于0。paddings[0][0]和paddings[0][1]指 定了第三个维度上padding的数量,paddings[1][0]和paddings[1][1]指定了第四个维度上padding的数量。 输出: - output,一个四维张量,数据类型和input一致。shape由input,blockShape和paddings共同决定,假设input shape为[n,c,h,w],则有 output.shape[0] = n * blockShape[0] * blockShape[1] output.shape[1] = c output.shape[2] = (h + paddings[0][0] + paddings[0][1]) / blockShape[0] output.shape[3] = (w + paddings[1][0] + paddings[1][1]) / blockShape[1] 要求(h + paddings[0][0] + paddings[0][1])和(w + paddings[1][0] + paddings[1][1])能被 blockShape[0]和blockShape[1]整除。 |
| OH_NN_OPS_SPLIT | Split算子沿axis维度将input拆分成多个张量,张量数量由outputNum指定。 输入: - input,n维张量。 参数: - outputNum,long,输出张量的数量,output_num类型为int。 - size_splits,一维张量,指定张量沿axis轴拆分后,每个张量的大小,size_splits 类型为 int。 如果size_splits的数据为空,则张量被拆分成大小均等的张量,此时要求input.shape[axis]可以被outputNum整除; 如果size_splits不为空,则要求 size_splits所有元素之和等于input.shape[axis]。 - axis,指定拆分的维度,axis类型为int。 输出: - outputs,一组n维张量,每一个张量类型和shape相同,每个张量的类型和input一致。 |
| OH_NN_OPS_SQRT | 给定一个张量,计算其平方根。 输入: - input,一个n维张量。 输出: - output,输入的平方根,一个n维张量,类型和shape和input一致。 |
| OH_NN_OPS_SQUARED_DIFFERENCE | 计算两个输入的差值并返回差值的平方。SquaredDifference算子支持张量和张量相减。 如果两个张量的TensorType不相同,Sub算子会将低精度的张量转成更高精度的类型。 如果两个张量的shape不同,要求两个张量可以通过broadcast拓展成相同shape的张量。 输入: - input1,被减数,input1是一个张量,张量的类型可以是NN_FLOAT16、NN_FLOAT32、NN_INT32或NN_BOOL。 - input2,减数,input2是一个张量,张量的类型可以是NN_FLOAT16、NN_FLOAT32、NN_INT32或NN_BOOL。 输出: - output,两个输入差值的平方。output的shape由input1和input2共同决定,input1和input2的shape相同时, output的shape和input1、input2相同;shape不同时,需要将input1或input2做broadcast操作后,相减得到output。 output的TensorType由两个输入中更高精度的TensorType决定。 |
| OH_NN_OPS_SQUEEZE | 去除axis中,长度为1的维度。支持int8量化输入假设input的shape为[2,1,1,2,2],axis为[0,1], 则output的shape为[2,1,2,2]。第0维到第一维之间,长度为0的维度被去除。 输入: - input,n维张量。 参数: - axis,指定删除的维度。axis可以是一个int64_t的整数或数组,整数的取值范围为[-n,n)。 输出: - output,输出张量。 |
| OH_NN_OPS_STACK | 将一组张量沿axis维度进行堆叠,堆叠前每个张量的维数为n,则堆叠后output维数为n+1。 输入: - input,Stack支持传入多个输入n维张量,每个张量要求shape相同且类型相同。 参数: - axis,一个整数,指定张量堆叠的维度。axis可以是负数,axis取值范围为[-(n+1),(n+1))。 输出: - output,将input沿axis维度堆叠的输出,n+一维张量,TensorType和input相同。 |
| OH_NN_OPS_STRIDED_SLICE | 跨步截取张量。 输入: - input,n维输入张量。 - begin,一维张量,begin的长度等于n,begin[i]指定第i维上截取的起点。 - end,一维张量,end的长度等于n,end[i]指定第i维上截取的终点。 - strides,一维张量,strides的长度等于n,strides[i]指定第i维上截取的步长。 参数: - beginMask,一个整数,用于解除begin的限制。将beginMask转成二进制表示,如果binary(beginMask)[i]==1, 则对于第i维,从第一个元素开始,以strides[i]为步长截取元素直到第end[i]-1个元素。 - endMask,个整数,用于解除end的限制。将endMask转成二进制表示,如果binary(endMask)[i]==1,则对于第i维, 从第begin[i]个元素起,以strides[i]为步长截取元素直到张量边界。 - ellipsisMask,一个整数,用于解除begin和end的限制。将ellipsisMask转成二进制表示,如果binary(ellipsisMask)[i]==1, 则对于第i维,从第一个元素开始,以strides[i]为补偿,截取元素直到张量边界。binary(ellipsisMask)仅允许有一位不为0。 - newAxisMask,一个整数,用于新增维度。将newAxisMask转成二进制表示,如果binary(newAxisMask)[i]==1,则在第i维插入长度为1的新维度。 - shrinkAxisMask,一个整数,用于压缩指定维度。将shrinkAxisMask转成二进制表示,如果binary(shrinkAxisMask)[i]==1, 则舍去第i维所有元素,第i维长度压缩至1。 输出: - 堆叠运算后的张量,数据类型与input相同。输出维度rank(input[0])+1 维。 |
| OH_NN_OPS_SUB | 计算两个输入的差值。 输入: - input1,一个张量,作为减法中的被减数。 - input2,一个张量,作为减法中的减数。 参数: - activationType,是一个整型常量,且必须是FuseType中含有的值。 在输出之前调用指定的激活。 输出: - output,两个输入相减的差。output的shape由input1和input2共同决定,当input1和input2的shape相同时,output的shape和input1、input2相同; shape不同时,需要将input1或input2做broadcast操作后,相减得到output。output的TensorType由两个输入中更高精度的TensorType决定。 |
| OH_NN_OPS_TANH | 计算输入张量的双曲正切值。 输入: - input,n维张量。 输出: - output,input的双曲正切,TensorType和张量shape和input相同。 |
| OH_NN_OPS_TILE | 以multiples指定的次数拷贝输入。 输入: - input,n维张量。 - multiples,一维张量,指定各个维度拷贝的次数。其长度m不小于input的维数n。 输出: - 张量,m维张量,TensorType与input相同。如果input和multiples长度相同, 则output和input维数一致,都是n维张量;如果multiples长度大于n,则用1填充input的维度, 再在各个维度上拷贝相应的次数,得到m维张量。 |
| OH_NN_OPS_TRANSPOSE | 根据permutation对input进行数据重排。 输入: - input,n维张量,待重排的张量。 - perm,一维张量,其长度和input的维数一致。 输出: - output,n维张量,output的TensorType与input相同,shape由input的shape和permutation共同决定。 |
| OH_NN_OPS_REDUCE_MEAN | keepDims为false时,计算指定维度上的平均值,减少input的维数;当keepDims为true时,计算指定维度上的平均值,保留相应的维度。 输入: - input,n维输入张量,n<8。 - axis,一维张量,指定计算均值的维度,axis中每个元素的取值范围为[-n,n)。 参数: - keepDims,布尔值,是否保留维度的标志位。 输出: - output,m维输出张量,数据类型和input相同。当keepDims为false时,m==n;当keepDims为true时,m<n。 |
| OH_NN_OPS_RESIZE_BILINEAR | 采用Bilinear方法,按给定的参数对input进行变形。 输入: - input,四维输入张量,input中的每个元素不能小于0。input排布必须是[batchSize,height,width,channels]。 参数: - newHeight,resize之后四维张量的height值。 - newWidth,resize之后四维张量的width值。 - preserveAspectRatio,一个布尔值,指示resize操作是否保持input的height/width比例。 - coordinateTransformMode,一个int32整数,指示Resize操作所使用的坐标变换方法,目前支持以下方法: - excludeOutside,一个int64浮点数。当excludeOutside=1时,超出input边界的采样权重被置为0,其余权重重新归一化处理。 输出: - output,n维输出张量,output的shape和数据类型和input相同。 |
| OH_NN_OPS_RSQRT | 求input平方根的倒数。 输入: - input,n维输入张量,input中的每个元素不能小于0,n<8。 输出: - output,n维输出张量,output的shape和数据类型和input相同。 |
| OH_NN_OPS_RESHAPE | 根据inputShape调整input的形状。 输入: - input,一个n维输入张量。 - InputShape,一个一维张量,表示输出张量的shape,需要是一个常量张量。 输出: - output,输出张量,数据类型和input一致,shape由inputShape决定。 |
| OH_NN_OPS_PRELU | 计算input和weight的PReLU激活值。 输入: - input,一个n维张量,如果n>=2,则要求input的排布为[BatchSize,…,Channels],第二个维度为通道数。 - output,input的PReLU激活值。形状和数据类型和input保持一致。 |
| OH_NN_OPS_RELU | 计算input的Relu激活值。 输入: - input,一个n维输入张量。 输出: - output,n维Relu输出张量,数据类型和shape和input一致。 |
| OH_NN_OPS_RELU6 | 计算input的Relu6激活值,即对input中每个元素x,计算min(max(x,0),6)。 输入: - input,一个n维输入张量。 输出: - output,n维Relu6输出张量,数据类型和shape和input一致。 |
| OH_NN_OPS_LAYER_NORM | 对一个张量从某一axis开始做层归一化。 输入: - input,一个n维输入张量。 - gamma,一个m维张量,gamma维度应该与input做归一化部分的shape一致。 - beta,一个m维张量,shape与gamma一样。 参数: - beginAxis,是一个NN_INT32的标量,指定开始做归一化的轴,取值范围是[1,rank(input))。 - epsilon,是一个NN_FLOAT32的标量,是归一化公式中的微小量,常用值是1e-7。 输出: - output,n维输出张量,数据类型和shape和input一致。 |
| OH_NN_OPS_REDUCE_PROD | 沿着axis指定的维度,计算input的累积。 输入: - input,n维输入张量,n<8。 - axis,一维张量,指定计算乘的维度,axis中每个元素的取值范围为[-n,n)。 参数: - keepDims,布尔值,是否保留维度的标志位。当keepDims为true时,output的维数和input保持一致;当keepDims为false时,output的维数缩减。 输出: - output,m维输出张量,数据类型和input相同。当keepDims为false时,m==n;当keepDims为true时,m<n。 |
| OH_NN_OPS_REDUCE_ALL | 当keepDims为false时,计算指定维度上的逻辑与,减少input的维数;当keepDims为true时,计算指定维度上的逻辑与,保留相应的维度。 输入: - input,n维输入张量,n<8。 - axis,一维张量,指定计算逻辑与的维度,axis中每个元素的取值范围为[-n,n)。 参数: - keepDims,布尔值,是否保留维度的标志位。 输出: - output,m维输出张量,数据类型和input相同。当keepDims为false时,m==n;当keepDims为true时,m<n。 |
| OH_NN_OPS_QUANT_DTYPE_CAST | 数据类型转换。 输入: - input,n维张量。 参数: - src_t,定义输入的数据类型。 - dst_t,定义输出的数据类型。 输出: - output,n维张量,数据类型由input决定,输出的形状和输入相同。 |
| OH_NN_OPS_TOP_K | 查找沿最后一个维度的k个最大条目的值和索引。 输入: - input,n维张量。 - k,指明是得到前k个数据以及其index。 参数: - sorted,如果为True,按照大到小排序,如果为False,按照小到大排序。 输出: - output0,最后一维的每个切片中的k个最大元素。 - output1,输入的最后一个维度内的值的索引。 |
| OH_NN_OPS_ARG_MAX | 返回跨轴的张量最大值的索引。 输入: - input,n维张量,输入张量(N,∗),其中∗意味着任意数量的附加维度。 参数: - axis,指定求最大值索引的维度。 - keep_dims,bool值,是否维持输入张量维度。 输出: - output,张量,轴上输入张量最大值的索引。 |
| OH_NN_OPS_UNSQUEEZE | 根据输入axis的值,增加一个维度。 输入: - input,n维张量。 参数: - axis,指定增加的维度。axis可以是一个整数或一组整数,整数的取值范围为[-n,n)。 输出: - output,输出张量。 |
| OH_NN_OPS_GELU | 高斯误差线性单元激活函数。output=0.5∗input∗(1+tanh(input/2)),不支持int量化输入。 输入: - input,一个n维输入张量。 输出: - output,n维Relu输出张量,数据类型和shape和input一致。 |
OH_NN_PerformanceMode
enum OH_NN_PerformanceMode
描述:
硬件的性能模式。
| 枚举值 | 描述 |
|---|---|
| OH_NN_PERFORMANCE_NONE | 无性能模式偏好。 |
| OH_NN_PERFORMANCE_LOW | 低能耗模式。 |
| OH_NN_PERFORMANCE_MEDIUM | 中性能模式。 |
| OH_NN_PERFORMANCE_HIGH | 高性能模式。 |
| OH_NN_PERFORMANCE_EXTREME | 极致性能模式。 |
OH_NN_Priority
enum OH_NN_Priority
描述:
模型推理任务优先级。
| 枚举值 | 描述 |
|---|---|
| OH_NN_PRIORITY_NONE | 无优先级偏好。 |
| OH_NN_PRIORITY_LOW | 低优先级。 |
| OH_NN_PRIORITY_MEDIUM | 中优先级。 |
| OH_NN_PRIORITY_HIGH | 高优先级。 |
OH_NN_ReturnCode
enum OH_NN_ReturnCode
描述:
Neural Network Runtime定义的错误码类型。
| 枚举值 | 描述 |
|---|---|
| OH_NN_SUCCESS | 操作成功。 |
| OH_NN_FAILED | 操作失败。 |
| OH_NN_INVALID_PARAMETER | 非法参数。 |
| OH_NN_MEMORY_ERROR | 内存相关的错误,包括:内存不足、内存数据拷贝失败、内存申请失败等。 |
| OH_NN_OPERATION_FORBIDDEN | 非法操作。 |
| OH_NN_NULL_PTR | 空指针异常。 |
| OH_NN_INVALID_FILE | 无效文件。 |
| OH_NN_UNAVALIDABLE_DEVICE | 硬件发生错误,错误可能包含:HDL服务崩溃。 |
| OH_NN_INVALID_PATH | 非法路径。 |
OH_NN_TensorType
enum OH_NN_TensorType
描述:
张量的类型。
张量通常用于设置模型的输入、输出和算子参数。
作为模型(或算子)的输入和输出时,需要将张量类型设置为OH_NN_TENSOR;当张量作为算子参数时,需要选择除OH_NN_TENSOR以外合适的枚举值,作为张量的类型。
假设正在设置OH_NN_OPS_CONV2D算子的pad参数,则需要将 OH_NN_Tensor实例的type属性设置为OH_NN_CONV2D_PAD。
其他算子参数的设置以此类推,枚举值的命名遵守OH_NN_{算子名称}_{属性名}的格式。
| 枚举值 | 描述 |
|---|---|
| OH_NN_TENSOR | 当张量作为模型(或算子)的输入或输出时,使用本枚举值。 |
| OH_NN_ADD_ACTIVATIONTYPE | 当张量作为Add算子的activationType参数时,使用本枚举值。 |
| OH_NN_AVG_POOL_KERNEL_SIZE | 当张量作为AvgPool算子的kernel_size参数时,使用本枚举值。 |
| OH_NN_AVG_POOL_STRIDE | 当张量作为AvgPool算子的stride参数时,使用本枚举值。 |
| OH_NN_AVG_POOL_PAD_MODE | 当张量作为AvgPool算子的pad_mode参数时,使用本枚举值。 |
| OH_NN_AVG_POOL_PAD | 当张量作为AvgPool算子的pad参数时,使用本枚举值。 |
| OH_NN_AVG_POOL_ACTIVATION_TYPE | 当张量作为AvgPool算子的activation_type参数时,使用本枚举值。 |
| OH_NN_BATCH_NORM_EPSILON | 当张量作为BatchNorm算子的eosilon参数时,使用本枚举值。 |
| OH_NN_BATCH_TO_SPACE_ND_BLOCKSIZE | 当张量作为BatchToSpaceND算子的blockSize参数时,使用本枚举值。 |
| OH_NN_BATCH_TO_SPACE_ND_CROPS | 当张量作为BatchToSpaceND算子的crops参数时,使用本枚举值。 |
| OH_NN_CONCAT_AXIS | 当张量作为Concat算子的axis参数时,使用本枚举值。 |
| OH_NN_CONV2D_STRIDES | 当张量作为Conv2D算子的strides参数时,使用本枚举值。 |
| OH_NN_CONV2D_PAD | 当张量作为Conv2D算子的pad参数,使用本枚举值。 |
| OH_NN_CONV2D_DILATION | 当张量作为Conv2D算子的dilation参数时,使用本枚举值。 |
| OH_NN_CONV2D_PAD_MODE | 当张量作为Conv2D算子的padMode参数时,使用本枚举值。 |
| OH_NN_CONV2D_ACTIVATION_TYPE | 当张量作为Conv2D算子的activationType参数时,使用本枚举值。 |
| OH_NN_CONV2D_GROUP | 当张量作为Conv2D算子的group参数时,使用本枚举值。 |
| OH_NN_CONV2D_TRANSPOSE_STRIDES | 当张量作为Conv2DTranspose算子的strides参数时,使用本枚举值。 |
| OH_NN_CONV2D_TRANSPOSE_PAD | 当张量作为Conv2DTranspose算子的pad参数时,使用本枚举值。 |
| OH_NN_CONV2D_TRANSPOSE_DILATION | 当张量作为Conv2DTranspose算子的dilation参数时,使用本枚举值。 |
| OH_NN_CONV2D_TRANSPOSE_OUTPUT_PADDINGS | 当张量作为Conv2DTranspose算子的outputPaddings参数时,使用本枚举值。 |
| OH_NN_CONV2D_TRANSPOSE_PAD_MODE | 当张量作为Conv2DTranspose算子的padMode参数时,使用本枚举值。 |
| OH_NN_CONV2D_TRANSPOSE_ACTIVATION_TYPE | 当张量作为Conv2DTranspose算子的activationType参数时,使用本枚举值。 |
| OH_NN_CONV2D_TRANSPOSE_GROUP | 当张量作为Conv2DTranspose算子的group参数时,使用本枚举值。 |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_STRIDES | 当张量作为DepthwiseConv2dNative算子的strides参数时,使用本枚举值。 |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD | 当张量作为DepthwiseConv2dNative算子的pad参数时,使用本枚举值。 |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_DILATION | 当张量作为DepthwiseConv2dNative算子的dilation参数时,使用本枚举值。 |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD_MODE | 当张量作为DepthwiseConv2dNative算子的padMode参数时,使用本枚举值。 |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_ACTIVATION_TYPE | 当张量作为DepthwiseConv2dNative算子的activationType参数时,使用本枚举值。 |
| OH_NN_DIV_ACTIVATIONTYPE | 当张量作为Div算子的activationType参数时,使用本枚举值。 |
| OH_NN_ELTWISE_MODE | 当张量作为Eltwise算子的mode参数时,使用本枚举值。 |
| OH_NN_FULL_CONNECTION_AXIS | 当张量作为FullConnection算子的axis参数时,使用本枚举值。 |
| OH_NN_FULL_CONNECTION_ACTIVATIONTYPE | 当张量作为FullConnection算子的activationType参数时,使用本枚举值。 |
| OH_NN_MATMUL_TRANSPOSE_A | 当张量作为Matmul算子的transposeA参数时,使用本枚举值。 |
| OH_NN_MATMUL_TRANSPOSE_B | 当张量作为Matmul算子的transposeB参数时,使用本枚举值。 |
| OH_NN_MATMUL_ACTIVATION_TYPE | 当张量作为Matmul算子的activationType参数时,使用本枚举值。 |
| OH_NN_MAX_POOL_KERNEL_SIZE | 当张量作为MaxPool算子的kernel_size参数时,使用本枚举值。 |
| OH_NN_MAX_POOL_STRIDE | 当张量作为MaxPool算子的stride参数时,使用本枚举值。 |
| OH_NN_MAX_POOL_PAD_MODE | 当张量作为MaxPool算子的pad_mode参数时,使用本枚举值。 |
| OH_NN_MAX_POOL_PAD | 当张量作为MaxPool算子的pad参数时,使用本枚举值。 |
| OH_NN_MAX_POOL_ACTIVATION_TYPE | 当张量作为MaxPool算子的activation_type参数时,使用本枚举值。 |
| OH_NN_MUL_ACTIVATION_TYPE | 当张量作为Mul算子的activationType参数时,使用本枚举值。 |
| OH_NN_ONE_HOT_AXIS | 当张量作为OneHot算子的axis参数时,使用本枚举值。 |
| OH_NN_PAD_CONSTANT_VALUE | 当张量作为Pad算子的constant_value参数时,使用本枚举值。 |
| OH_NN_SCALE_ACTIVATIONTYPE | 当张量作为Scale算子的activationType参数时,使用本枚举值。 |
| OH_NN_SCALE_AXIS | 当张量作为Scale算子的axis参数时,使用本枚举值。 |
| OH_NN_SOFTMAX_AXIS | 当张量作为Softmax算子的axis参数时,使用本枚举值。 |
| OH_NN_SPACE_TO_BATCH_ND_BLOCK_SHAPE | 当张量作为SpaceToBatchND算子的BlockShape参数时,使用本枚举值。 |
| OH_NN_SPACE_TO_BATCH_ND_PADDINGS | 当张量作为SpaceToBatchND算子的Paddings参数时,使用本枚举值。 |
| OH_NN_SPLIT_AXIS | 当张量作为Split算子的Axis参数时,使用本枚举值。 |
| OH_NN_SPLIT_OUTPUT_NUM | 当张量作为Split算子的OutputNum参数时,使用本枚举值。 |
| OH_NN_SPLIT_SIZE_SPLITS | 当张量作为Split算子的SizeSplits参数时,使用本枚举值。 |
| OH_NN_SQUEEZE_AXIS | 当张量作为Squeeze算子的Axis参数时,使用本枚举值。 |
| OH_NN_STACK_AXIS | 当张量作为Stack算子的Axis参数时,使用本枚举值。 |
| OH_NN_STRIDED_SLICE_BEGIN_MASK | 当张量作为StridedSlice算子的BeginMask参数时,使用本枚举值。 |
| OH_NN_STRIDED_SLICE_END_MASK | 当张量作为StridedSlice算子的EndMask参数时,使用本枚举值。 |
| OH_NN_STRIDED_SLICE_ELLIPSIS_MASK | 当张量作为StridedSlice算子的EllipsisMask参数时,使用本枚举值。 |
| OH_NN_STRIDED_SLICE_NEW_AXIS_MASK | 当张量作为StridedSlice算子的NewAxisMask参数时,使用本枚举值。 |
| OH_NN_STRIDED_SLICE_SHRINK_AXIS_MASK | 当张量作为StridedSlice算子的ShrinkAxisMask参数时,使用本枚举值。 |
| OH_NN_SUB_ACTIVATIONTYPE | 当张量作为Sub算子的ActivationType参数时,使用本枚举值。 |
| OH_NN_REDUCE_MEAN_KEEP_DIMS | 当张量作为ReduceMean算子的keep_dims参数时,使用本枚举值。 |
| OH_NN_RESIZE_BILINEAR_NEW_HEIGHT | 当张量作为ResizeBilinear算子的new_height参数时,使用本枚举值。 |
| OH_NN_RESIZE_BILINEAR_NEW_WIDTH | 当张量作为ResizeBilinear算子的new_width参数时,使用本枚举值。 |
| OH_NN_RESIZE_BILINEAR_PRESERVE_ASPECT_RATIO | 当张量作为ResizeBilinear算子的preserve_aspect_ratio参数时,使用本枚举值。 |
| OH_NN_RESIZE_BILINEAR_COORDINATE_TRANSFORM_MODE | 当张量作为ResizeBilinear算子的coordinate_transform_mode参数时,使用本枚举值。 |
| OH_NN_RESIZE_BILINEAR_EXCLUDE_OUTSIDE | 当张量作为ResizeBilinear算子的exclude_outside参数时,使用本枚举值。 |
| OH_NN_LAYER_NORM_BEGIN_NORM_AXIS | 当张量作为LayerNorm算子的beginNormAxis参数时,使用本枚举值。 |
| OH_NN_LAYER_NORM_EPSILON | 当张量作为LayerNorm算子的epsilon参数时,使用本枚举值。 |
| OH_NN_LAYER_NORM_BEGIN_PARAM_AXIS | 当张量作为LayerNorm算子的beginParamsAxis参数时,使用本枚举值。 |
| OH_NN_LAYER_NORM_ELEMENTWISE_AFFINE | 当张量作为LayerNorm算子的elementwiseAffine参数时,使用本枚举值。 |
| OH_NN_REDUCE_PROD_KEEP_DIMS | 当张量作为ReduceProd算子的keep_dims参数时,使用本枚举值。 |
| OH_NN_REDUCE_ALL_KEEP_DIMS | 当张量作为ReduceAll算子的keep_dims参数时,使用本枚举值。 |
| OH_NN_QUANT_DTYPE_CAST_SRC_T | 当张量作为QuantDTypeCast算子的src_t参数时,使用本枚举值。 |
| OH_NN_QUANT_DTYPE_CAST_DST_T | 当张量作为QuantDTypeCast算子的dst_t参数时,使用本枚举值。 |
| OH_NN_TOP_K_SORTED | 当张量作为Topk算子的Sorted参数时,使用本枚举值。 |
| OH_NN_ARG_MAX_AXIS | 当张量作为ArgMax算子的axis参数时,使用本枚举值。 |
| OH_NN_ARG_MAX_KEEPDIMS | 当张量作为ArgMax算子的keepDims参数时,使用本枚举值。 |
| OH_NN_UNSQUEEZE_AXIS | 当张量作为Unsqueeze算子的Axis参数时,使用本枚举值。 |
函数说明
OH_NNCompilation_Build()
OH_NN_ReturnCode OH_NNCompilation_Build (OH_NNCompilation * compilation)
描述:
进行模型编译。
完成编译配置后,调用本方法指示模型编译已完成。编译实例将模型和编译选项推送至硬件设备进行编译。
在调用本方法后,无法进行额外的编译操作,调用 OH_NNCompilation_SetDevice、OH_NNCompilation_SetCache、 OH_NNCompilation_SetPerformanceMode、 OH_NNCompilation_SetPriority和OH_NNCompilation_EnableFloat16 方法将返回OH_NN_OPERATION_FORBIDDEN。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的指针。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNCompilation_Construct()
OH_NNCompilation* OH_NNCompilation_Construct (const OH_NNModel * model)
描述:
创建OH_NNCompilation类型的编译实例。
使用OH_NNModel模块完成模型的构造后,借助OH_NNCompilation模块提供的接口,将模型传递到底层硬件完成编译。本方法接受一个 OH_NNModel实例,创建出OH_NNCompilation实例;通过 OH_NNCompilation_SetDevice方法,设置编译的设备,最后调用 OH_NNCompilation_Build完成编译。
除了计算硬件的选择,OH_NNCompilation模块支持模型缓存、性能偏好、优先级设置、float16计算等特性,参考以下方法:
调用本方法创建OH_NNCompilation后,OH_NNModel实例可以释放。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的指针。 |
返回:
返回一个指向OH_NNCompilation实例的指针。
OH_NNCompilation_Destroy()
void OH_NNCompilation_Destroy (OH_NNCompilation ** compilation)
描述:
释放Compilation对象。
调用OH_NNCompilation_Construct创建的编译实例需要调用本方法主动释放,否则将造成内存泄漏。
如果compilation为空指针或者*compilation为空指针,本方法只打印warning日志,不执行释放逻辑。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的二级指针。编译实例销毁后,本方法将*compilation主动设置为空指针。 |
OH_NNCompilation_EnableFloat16()
OH_NN_ReturnCode OH_NNCompilation_EnableFloat16 (OH_NNCompilation * compilation, bool enableFloat16 )
描述:
是否以float16的浮点数精度计算。
Neural Network Runtime目前仅支持构造float32浮点模型和int8量化模型。在支持float16精度的硬件上调用本方法, float32浮点数精度的模型将以float16的精度执行计算,以减少内存占用和执行时间。
在不支持float16精度计算的硬件上调用本方法,将返回OH_NN_UNAVALIDABLE_DEVICE错误码。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的指针。 |
| enableFloat16 | Float16低精度计算标志位。设置为true时,执行Float16推理;设置为false时,执行float32推理。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNCompilation_SetCache()
OH_NN_ReturnCode OH_NNCompilation_SetCache (OH_NNCompilation * compilation, const char * cachePath, uint32_t version )
描述:
设置编译后的模型缓存路径和缓存版本。
在支持缓存的硬件上,模型在硬件驱动层编译后可以保存为缓存文件,下次编译时直接从缓存文件读取模型,减少重新编译的耗时。本方法接受缓存路径和版本,根据缓存 路径中和版本的不同情况,本方法采取不同的行为:
-
缓存路径指定的目录下没有文件: 将编译后的模型缓存到目录下,设置缓存版本等于version。
-
缓存路径指定的目录下存在完整的缓存文件,且版本号 == version: 读取路径下的缓存文件,传递到底层硬件中转换为可以执行的模型实例。
-
缓存路径指定的目录下存在完整的缓存文件,但版本号 < version: 路径下的缓存文件需要更新,模型在底层硬件完成编译后,覆写路径下的缓存文件,将版本号更新为version。
-
缓存路径指定的目录下存在完整的缓存文件,但版本号 > version: 路径下的缓存文件版本高于version,不读取缓存文件,同时返回OH_NN_INVALID_PARAMETER错误码。
-
缓存路径指定的目录下的缓存文件不完整或没有缓存文件的访问权限: 返回OH_NN_INVALID_FILE错误码。
-
缓存目录不存在,或者没有访问权限: 返回OH_NN_INVALID_PATH错误码。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的指针。 |
| cachePath | 模型缓存文件目录,本方法在cachePath目录下为不同的硬件创建缓存目录。建议每个模型使用单独的缓存目录。 |
| version | 缓存版本。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNCompilation_SetDevice()
OH_NN_ReturnCode OH_NNCompilation_SetDevice (OH_NNCompilation * compilation, size_t deviceID )
描述:
指定模型编译和计算的硬件。
编译阶段,需要指定模型编译和执行计算的硬件设备。先调用OH_NNDevice_GetAllDevicesID获取可用的设备ID,通过OH_NNDevice_GetType和OH_NNDevice_GetType获取设备信息后,将期望编译执行的设备ID传入本方法进行设置。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的指针。 |
| deviceID | 指定的硬件ID。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNCompilation_SetPerformanceMode()
OH_NN_ReturnCode OH_NNCompilation_SetPerformanceMode (OH_NNCompilation * compilation, OH_NN_PerformanceMode performanceMode )
描述:
设置模型计算的性能模式。
Neural Network Runtime支持为模型计算设置性能模式,满足低功耗到极致性能的需求。
如果编译阶段没有调用本方法设置性能模式, 编译实例为模型默认分配OH_NN_PERFORMANCE_NONE模式。
在OH_NN_PERFORMANCE_NONE 模式下,硬件按默认的性能模式执行计算。
在不支持性能模式设置的硬件上调用本方法,将返回OH_NN_UNAVALIDABLE_DEVICE错误码。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的指针。 |
| performanceMode | 指定性能模式,可选的性能模式参考OH_NN_PerformanceMode。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNCompilation_SetPriority()
OH_NN_ReturnCode OH_NNCompilation_SetPriority (OH_NNCompilation * compilation, OH_NN_Priority priority )
描述:
设置模型计算的优先级。
Neural Network Runtime 支持为模型设置计算优先级,优先级仅作用于相同uid进程创建的模型,不同uid进程、不同设备的优先级不会 相互影响。
在不支持优先级设置的硬件上调用本方法,将返回OH_NN_UNAVALIDABLE_DEVICE错误码。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的指针。 |
| priority | 指定优先级,可选的优先级参考OH_NN_Priority。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNDevice_GetAllDevicesID()
OH_NN_ReturnCode OH_NNDevice_GetAllDevicesID (const size_t ** allDevicesID, uint32_t * deviceCount )
描述:
获取对接到 Neural Network Runtime 的硬件ID。
每个硬件在 Neural Network Runtime 中存在唯一且固定ID,本方法通过uin32_t数组返回当前设备上已经对接的硬件ID。
硬件ID通过size_t数组返回,数组的每个元素是单个硬件的ID值。数组内存由Neural Network Runtime管理。在下次调用本方法前, 数据指针有效。
参数:
| 名称 | 描述 |
|---|---|
| allDevicesID | 指向size_t数组的指针。要求传入的(*allDevicesID)为空指针,否则返回OH_NN_INVALID_PARAMETER。 |
| deviceCount | uint32_t类型的指针,用于返回(*allDevicesID)的长度。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNDevice_GetName()
OH_NN_ReturnCode OH_NNDevice_GetName (size_t deviceID, const char ** name )
描述:
获取指定硬件的类型信息。
通过deviceID指定计算硬件,获取硬件的名称。硬件ID需要调用OH_NNDevice_GetAllDevicesID获取。
参数:
| 名称 | 描述 |
|---|---|
| deviceID | 指定硬件ID。 |
| name | 指向char数组的指针,要求传入的(*char)为空指针,否则返回OH_NN_INVALID_PARAMETER。 (*name)以C风格字符串保存硬件名称,数组以'\0'结尾。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNDevice_GetType()
OH_NN_ReturnCode OH_NNDevice_GetType (size_t deviceID, OH_NN_DeviceType * deviceType )
描述:
获取指定硬件的类别信息。
通过deviceID指定计算硬件,获取硬件的类别。目前 Neural Network Runtime 支持的设备类型有:
-
CPU设备:OH_NN_CPU
-
GPU设备:OH_NN_GPU
-
机器学习专用加速器:OH_NN_ACCELERATOR
-
不属于以上类型的其他硬件类型:OH_NN_OTHERS
参数:
| 名称 | 描述 |
|---|---|
| deviceID | 指定硬件ID。 |
| deviceType | 指向OH_NN_DeviceType实例的指针,返回硬件的类别信息。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNExecutor_AllocateInputMemory()
OH_NN_Memory* OH_NNExecutor_AllocateInputMemory (OH_NNExecutor * executor, uint32_t inputIndex, size_t length )
描述:
在硬件上为单个输入申请共享内存。
Neural Network Runtime 提供主动申请硬件共享内存的方法。通过指定执行器和输入索引值,本方法在单个输入关联的硬件 上,申请大小为length的共享内存,通过OH_NN_Memory实例返回。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| inputIndex | 输入的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输入数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,inputIndices为{1,5,9}, 则在申请输入内存时,三个输入的索引值分别为{0,1,2}。 |
| length | 申请的内存字节。 |
返回:
指向OH_NN_Memory实例的指针。
OH_NNExecutor_AllocateOutputMemory()
OH_NN_Memory* OH_NNExecutor_AllocateOutputMemory (OH_NNExecutor * executor, uint32_t outputIndex, size_t length )
描述:
在硬件上为单个输出申请共享内存。
Neural Network Runtime提供主动申请硬件共享内存的方法。通过指定执行器和输出索引值,本方法在单个输出关联的硬件上,申请大小为length的共享内存,通过OH_NN_Memory实例返回。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| outputIndex | 输出的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输出数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,outputIndices为{4,6,8}, 则在申请输出内存时,三个输出的索引值分别为{0,1,2}。 |
| length | 申请的内存字节。 |
返回:
指向OH_NN_Memory实例的指针。
OH_NNExecutor_Construct()
OH_NNExecutor* OH_NNExecutor_Construct (OH_NNCompilation * compilation)
描述:
创建OH_NNExecutor类型的执行器实例
本方法接受一个编译器,构造一个与硬件关联的模型推理执行器。通过OH_NNExecutor_SetInput设置模型输入数据, 设置输入数据后,调用OH_NNExecutor_Run方法执行推理,最后通过 OH_NNExecutor_SetOutput获取计算结果。
调用本方法创建OH_NNExecutor实例后,如果不需要创建其他执行器,可以安全释放OH_NNCompilation实例。
参数:
| 名称 | 描述 |
|---|---|
| compilation | 指向OH_NNCompilation实例的指针。 |
返回:
返回指向OH_NNExecutor实例的指针。
OH_NNExecutor_Destroy()
void OH_NNExecutor_Destroy (OH_NNExecutor ** executor)
描述:
销毁执行器实例,释放执行器占用的内存。
调用OH_NNExecutor_Construct创建的执行器实例需要调用本方法主动释放,否则将造成内存泄漏。
如果executor为空指针或者*executor为空指针,本方法只打印warning日志,不执行释放逻辑。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的二级指针。 |
OH_NNExecutor_DestroyInputMemory()
void OH_NNExecutor_DestroyInputMemory (OH_NNExecutor * executor, uint32_t inputIndex, OH_NN_Memory ** memory )
描述:
释放OH_NN_Memory实例指向的输入内存。
调用OH_NNExecutor_AllocateInputMemory创建的内存实例,需要主动调用本方法进行释放,否则将造成内存泄漏。 inputIndex和memory的对应关系需要和创建内存实例时保持一致。
如果memory或*memory为空指针,本方法只打印warning日志,不执行释放逻辑。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| inputIndex | 输入的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输入数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,inputIndices为{1,5,9}, 则在执行释放输入内存时,三个输入的索引值分别为{0,1,2}。 |
| memory | 指向OH_NN_Memory实例的二级指针。共享内存销毁后,本方法将*memory主动设置为空指针。 |
OH_NNExecutor_DestroyOutputMemory()
void OH_NNExecutor_DestroyOutputMemory (OH_NNExecutor * executor, uint32_t outputIndex, OH_NN_Memory ** memory )
描述:
释放OH_NN_Memory实例指向的输出内存。
调用OH_NNExecutor_AllocateOutputMemory创建的内存实例,需要主动调用本方法进行释放,否则将造成内存泄漏。 outputIndex和memory的对应关系需要和创建内存实例时保持一致。
如果memory或*memory为空指针,本方法只打印warning日志,不执行释放逻辑。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| outputIndex | 输出的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输出数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,outputIndices为{4,6,8}, 则在执行释放输出内存时,三个输出的索引值分别为{0,1,2}。 |
| memory | 指向OH_NN_Memory实例的二级指针。共享内存销毁后,本方法将*memory主动设置为空指针。 |
OH_NNExecutor_GetOutputShape()
OH_NN_ReturnCode OH_NNExecutor_GetOutputShape (OH_NNExecutor * executor, uint32_t outputIndex, int32_t ** shape, uint32_t * shapeLength )
描述:
获取输出张量的维度信息。
调用OH_NNExecutor_Run完成单次推理后,本方法获取指定输出的维度信息和维数。在动态形状输入、输出的场景中常用。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| outputIndex | 输出的索引值。与调用OH_NNModel_SpecifyInputsAndOutputs时输出数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,outputIndices为{4,6,8}, 则在获取输出张量维度信息的阶段,三个输出的索引值分别为{0,1,2}。 |
| shape | 指向int32_t数组的指针,数组中的每个元素值,是输出张量在每个维度上的长度。 |
| shapeLength | uint32_t类型的指针,返回输出的维数。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNExecutor_Run()
OH_NN_ReturnCode OH_NNExecutor_Run (OH_NNExecutor * executor)
描述:
执行推理。
在执行器关联的硬件上,执行模型的端到端推理计算。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNExecutor_SetInput()
OH_NN_ReturnCode OH_NNExecutor_SetInput (OH_NNExecutor * executor, uint32_t inputIndex, const OH_NN_Tensor * tensor, const void * dataBuffer, size_t length )
描述:
设置模型单个输入的数据。
本方法将dataBuffer中,长度为length个字节的数据,拷贝到底层硬件的共享内存。inputIndex指定设置的输入,tensor用于设置输入的 形状、类型、量化参数等信息。
由于Neural Network Runtime支持动态输入形状的模型,在固定形状输入和动态形状输入的场景下,本方法采取不同的处理策略:
-
固定形状输入的场景:tensor各属性必须和构图阶段调用OH_NNModel_AddTensor添加的张量保持一致;
-
动态形状输入的场景:在构图阶段,由于动态输入的形状不确定,调用本方法时,要求tensor.dimensions中的每个值必须大于0, 以确定执行计算阶段输入的形状。设置形状时,只允许调整数值为-1的维度。假设在构图阶段,输入A的维度为 [-1, 224, 224, 3],调用本方法时,只能调整第一个维度的尺寸,如:[3, 224, 224, 3]。调整其他维度将返回OH_NN_INVALID_PARAMETER。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| inputIndex | 输入的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输入数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,inputIndices为{1,5,9}, 则在设置输入的阶段,三个输入的索引值分别为{0,1,2}。 |
| tensor | 设置输入数据对应的张量。 |
| dataBuffer | 指向输入数据的指针。 |
| length | 数据缓冲区的字节长度。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNExecutor_SetInputWithMemory()
OH_NN_ReturnCode OH_NNExecutor_SetInputWithMemory (OH_NNExecutor * executor, uint32_t inputIndex, const OH_NN_Tensor * tensor, const OH_NN_Memory * memory )
描述:
将OH_NN_Memory实例指向的硬件共享内存,指定为单个输入使用的共享内存。
在需要自行管理内存的场景下,本方法将执行输入和OH_NN_Memory内存实例绑定。执行计算时,底层硬件从内存实例指向的共享内存中读取 输入数据。通过本方法,可以实现设置输入、执行计算、读取输出的并发执行,提升数据流的推理效率。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| inputIndex | 输入的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输入数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,inputIndices为{1,5,9}, 则在指定输入的共享内存时,三个输入的索引值分别为{0,1,2}。 |
| tensor | 指向OH_NN_Tensor的指针,设置单个输入所对应的张量。 |
| memory | 指向OH_NN_Memory的指针。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNExecutor_SetOutput()
OH_NN_ReturnCode OH_NNExecutor_SetOutput (OH_NNExecutor * executor, uint32_t outputIndex, void * dataBuffer, size_t length )
描述:
设置模型单个输出的缓冲区。
本方法将dataBuffer指向的缓冲区与outputIndex指定的输出绑定,缓冲区的长度由length指定。
调用OH_NNExecutor_Run完成单次模型推理后,Neural Network Runtime将比对dataBuffer指向的缓冲区与 输出数据的长度,根据不同情况,返回不同结果:
-
如果缓冲区大于或等于数据长度:则推理后的结果将拷贝至缓冲区,并返回OH_NN_SUCCESS,可以通过访问dataBuffer读取推理结果。
-
如果缓冲区小于数据长度:则OH_NNExecutor_Run将返回OH_NN_INVALID_PARAMETER, 并输出日志告知缓冲区太小的信息。
参数:
| 名称 | 描述 |
|---|---|
| executor | 指向OH_NNExecutor实例的指针。 |
| outputIndex | 输出的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输出数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,outputIndices为{4,6,8}, 则设置输出缓冲区时,三个输出的索引值分别为{0,1,2}。 |
| dataBuffer | 指向输出数据的指针。 |
| length | 数据缓冲区的字节长度。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNExecutor_SetOutputWithMemory()
OH_NN_ReturnCode OH_NNExecutor_SetOutputWithMemory (OH_NNExecutor * executor, uint32_t outputIndex, const OH_NN_Memory * memory )
描述:
将OH_NN_Memory实例指向的硬件共享内存,指定为单个输出使用的共享内存。
在需要自行管理内存的场景下,本方法将执行输出和OH_NN_Memory内存实例绑定。执行计算时,底层硬件将计算结果直接写入内存实例指向 的共享内存。通过本方法,可以实现设置输入、执行计算、读取输出的并发执行,提升数据流的推理效率。
参数:
| 名称 | 描述 |
|---|---|
| executor | 执行器。 |
| outputIndex | 输出的索引值,与调用OH_NNModel_SpecifyInputsAndOutputs时输出数据的顺序一致。假设调用OH_NNModel_SpecifyInputsAndOutputs时,outputIndices为{4,6,8}, 则在指定输出的共享内存时,三个输出的索引值分别为{0,1,2}。 |
| memory | 指向OH_NN_Memory的指针。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNModel_AddOperation()
OH_NN_ReturnCode OH_NNModel_AddOperation (OH_NNModel * model, OH_NN_OperationType op, const OH_NN_UInt32Array * paramIndices, const OH_NN_UInt32Array * inputIndices, const OH_NN_UInt32Array * outputIndices )
描述:
向模型实例中添加算子。
本方法向模型实例中添加算子,算子类型由op指定,算子的参数、输入和输出由paramIndices、inputIndices和 outputIndices指定。本方法将对算子参数的属性和输入输出的数量进行校验,这些属性需要在调用 OH_NNModel_AddTensor添加张量的时候正确设置。每个算子期望的参数、输入和输出属性请参考 OH_NN_OperationType。
paramIndices、inputIndices和outputIndices中存储的是张量的索引值,每个索引值根据张量添加进模型的顺序决定,正确 设置并添加算子要求准确设置每个张量的索引值。张量的添加参考OH_NNModel_AddTensor。
如果添加算子时,添加了额外的参数(非算子需要的参数),本方法返回OH_NN_INVALID_PARAMETER;如果没有设置算子参数, 则算子按默认值设置缺省的参数,默认值请参考OH_NN_OperationType。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的指针。 |
| op | 指定添加的算子类型,取值请参考OH_NN_OperationType的枚举值。 |
| paramIndices | OH_NN_UInt32Array实例的指针,设置算子的参数。 |
| inputIndices | OH_NN_UInt32Array实例的指针,指定算子的输入。 |
| outputIndices | OH_NN_UInt32Array实例的指针,设置算子的输出。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNModel_AddTensor()
OH_NN_ReturnCode OH_NNModel_AddTensor (OH_NNModel * model, const OH_NN_Tensor * tensor )
描述:
向模型实例中添加张量。
Neural Network Runtime模型中的数据节点和算子参数均由模型的张量构成。本方法根据tensor,向model实 例中添加张量。张量添加的顺序是模型中记录张量的索引值,OH_NNModel_SetTensorData、 OH_NNModel_AddOperation和OH_NNModel_SpecifyInputsAndOutputs 方法根据该索引值,指定不同的张量。
Neural Network Runtime支持动态形状输入和输出。在添加动态形状的数据节点时,需要将tensor.dimensions中支持动态 变化的维度设置为-1。例如:一个四维tensor,将tensor.dimensions设置为[1, -1, 2, 2],表示其第二个维度支持 动态变化。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的指针。 |
| tensor | OH_NN_Tensor张量的指针,tensor指定了添加到模型实例中张量的属性。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNModel_Construct()
OH_NNModel* OH_NNModel_Construct (void )
描述:
创建OH_NNModel类型的模型实例,搭配OH_NNModel模块提供的其他接口,完成模型实例的构造。
在开始构图前,先调用OH_NNModel_Construct创建模型实例,根据模型的拓扑结构,调用 OH_NNModel_AddTensor、OH_NNModel_AddOperation和 OH_NNModel_SetTensorData方法,填充模型的数据节点和算子节点;然后调用 OH_NNModel_SpecifyInputsAndOutputs指定模型的输入和输出;当构造完模型的拓扑结构,调用 OH_NNModel_Finish完成模型的构建。
模型实例使用完毕后,需要调用OH_NNModel_Destroy销毁模型实例,避免内存泄漏。
返回:
返回一个指向OH_NNModel实例的指针。
OH_NNModel_Destroy()
void OH_NNModel_Destroy (OH_NNModel ** model)
描述:
释放模型实例。
调用OH_NNModel_Construct创建的模型实例需要调用本方法主动释放,否则将造成内存泄漏。
如果model为空指针或者*model为空指针,本方法只打印warning日志,不执行释放逻辑。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的二级指针。模型实例销毁后,本方法将*model主动设置为空指针。 |
OH_NNModel_Finish()
OH_NN_ReturnCode OH_NNModel_Finish (OH_NNModel * model)
描述:
完成模型构图。
完成模型拓扑结构的搭建后,调用本方法指示构图已完成。
在调用本方法后,无法进行额外的构图操作,调用 OH_NNModel_AddTensor、OH_NNModel_AddOperation、 OH_NNModel_SetTensorData和 OH_NNModel_SpecifyInputsAndOutputs将返回OH_NN_OPERATION_FORBIDDEN。
在调用OH_NNModel_GetAvailableOperations和OH_NNCompilation_Construct 之前,必须先调用本方法完成构图。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的指针。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNModel_GetAvailableOperations()
OH_NN_ReturnCode OH_NNModel_GetAvailableOperations (OH_NNModel * model, size_t deviceID, const bool ** isSupported, uint32_t * opCount )
描述:
查询硬件对模型内所有算子的支持情况,通过布尔值序列指示支持情况。
查询底层硬件对模型实例内每个算子的支持情况,硬件由deviceID指定,结果将通过isSupported指向的数组表示。如果支持第i个算子,则 (*isSupported)[i] == true,否则为 false。
本方法成功执行后,(*isSupported)将指向记录算子支持情况的bool数组,数组长度和模型实例的算子数量相等。该数组对应的内存由 Neural Network Runtime管理,在模型实例销毁或再次调用本方法后自动销毁。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的指针。 |
| deviceID | 指定查询的硬件ID,通过OH_NNDevice_GetAllDevicesID获取。 |
| isSupported | 指向bool数组的指针。调用本方法时,要求(*isSupported)为空指针,否则返回OH_NN_INVALID_PARAMETER。 |
| opCount | 模型实例中算子的数量,对应(*isSupported)数组的长度。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNModel_SetTensorData()
OH_NN_ReturnCode OH_NNModel_SetTensorData (OH_NNModel * model, uint32_t index, const void * dataBuffer, size_t length )
描述:
设置张量的数值。
对于具有常量值的张量(如模型的权重),需要在构图阶段使用本方法设置数值。张量的索引值根据张量添加进模型的顺序决定,张量的添加参考 OH_NNModel_AddTensor。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的指针。 |
| index | 张量的索引值。 |
| dataBuffer | 指向真实数据的指针。 |
| length | 数据缓冲区的长度。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。
OH_NNModel_SpecifyInputsAndOutputs()
OH_NN_ReturnCode OH_NNModel_SpecifyInputsAndOutputs (OH_NNModel * model, const OH_NN_UInt32Array * inputIndices, const OH_NN_UInt32Array * outputIndices )
描述:
指定模型的输入输出。
模型实例需要指定张量作为端到端的输入和输出,设置为输入和输出的张量不能使用OH_NNModel_SetTensorData设置 数值,需要在执行阶段调用OH_NNExecutor的方法设置输入、输出数据。
张量的索引值根据张量添加进模型的顺序决定,张量的添加参考 OH_NNModel_AddTensor。
暂时不支持异步设置模型输入输出。
参数:
| 名称 | 描述 |
|---|---|
| model | 指向OH_NNModel实例的指针。 |
| inputIndices | OH_NN_UInt32Array实例的指针,指定算子的输入。 |
| outputIndices | OH_NN_UInt32Array实例的指针,指定算子的输出。 |
返回:
函数执行的结果状态。执行成功返回OH_NN_SUCCESS;失败返回具体错误码,具体失败错误码可参考OH_NN_ReturnCode。