Introduction to Function Flow Runtime Kit
Introduction
Function Flow Runtime Kit provides a concurrent programming framework that allows you to develop an application by creating tasks and describing their dependencies. It supports data dependency management, task executor, and system event processing. It adopts coroutine-based task execution to support more concurrent tasks and improve the thread usage with fewer system threads. It leverages the computing resources of the multi-core platform to ensure intensive resource management. It solves the problem of thread resource abuse and provides the ultimate user experience.
Basic Concepts
Function Flow is a task-based and data-driven concurrent programming model that allows you to develop an application by creating tasks and describing their dependencies. Function Flow Runtime (FFRT) is a software runtime library that works with the Function Flow programming model. It is used to schedule and execute tasks of an application developed on the Function Flow programming model. Specifically, FFRT automatically and concurrently schedules and executes tasks of the application based on the task dependency status and available resources, so that you can focus on feature development.
Programming Models
| Item | Thread Programming Model | FFRT Programming Model |
|---|---|---|
| Degree of Parallelism (DOP) mining mode | Programmers create multiple threads and assign tasks to them for parallel execution to achieve the optimal runtime performance. | Programmers, with the help of compilers or programming language features, decompose the application into tasks and describe their data dependencies during static programming. The scheduler allocates tasks to worker threads for execution. |
| Owner for creating threads | Programmers are responsible for creating threads. The maximum number of threads that can be created is not under control. | The scheduler is responsible for creating and managing worker threads. Programmers cannot directly create threads. |
| Load balancing | Programmers map tasks to threads during static programming. Improper mapping or uncertain task execution time will cause a load imbalance among threads. | A ready task is automatically scheduled to an idle thread for execution, reducing the load imbalance among threads. |
| Scheduling overhead | Thread scheduling is implemented by a kernel-mode scheduler, resulting in high scheduling overhead. | Thread scheduling is implemented by a user-mode coroutine scheduler, requiring less scheduling overhead. In addition, FFRT can further reduce the scheduling overhead through hardware-based scheduling offload. |
| Dependency expression | A thread is in the executable state once it is created, and it is executed parallelly with other threads, causing frequent thread switching. | FFRT determines whether a task can be executed based on the input and output dependencies explicitly expressed during task creation. If the input dependencies do not meet the requirements, the task is not scheduled. |
Function Flow
The Function Flow programming model allows you to develop an application by creating tasks and describing their dependencies. Its most outstanding features are task-based and data-driven.
Task-based
Task-based means that you can use tasks to express an application and schedule the tasks at runtime.
A task is defined as a developer-oriented programming clue and a runtime-oriented execution object. It usually contains a set of sequential instructions and a data context environment to run the instructions.
Tasks in the Function Flow programming model have the following features:
- The dependency between tasks can be specified in data-driven form.
- Tasks can be nested. That is, when a task is being executed, a new task can be generated and delivered to that task to form a parent-child relationship.
- Simultaneous operations, such as wait, lock, and condition variables, are supported.
NOTE
The task granularity determines the number of concurrent tasks and therefore affects the application execution performance. A small granularity increases the scheduling overhead, whereas a large granularity decreases the DOP. The minimum task granularity allowed in the Function Flow programming model is 100 μs.
Data-driven
Data-driven means that the dependency between tasks is expressed through data dependencies.
Data objects associated with a task are read and written during task execution. In the Function Flow programming model, a data object is abstracted as a data signature. They are in one-to-one mapping.
Data dependencies, consisting of in_deps and out_deps, are abstracted as a list of data signatures mapping to the data objects manipulated by the task. When the signature of a data object appears in in_deps of a task, the task is a consumer task of the data object. The execution of a consumer task does not change the content of the input data object. When the signature of a data object appears in out_deps of a task, the task is a producer task of the data object. The execution of a producer task changes the content of the output data object and generates a new version of the data object.
A data object may have multiple versions. Each version corresponds to one producer task and zero, one, or more consumer tasks. A sequence of the data object versions and the version-specific producer task and consumer tasks are defined according to the delivery sequence of the producer task and consumer tasks.
When all producer tasks and consumer tasks of the data object of all the available versions are executed, the data dependency is removed. In this case, the task enters the ready state and can be scheduled for execution.
With the data-driven dependency expression, FFRT can dynamically build different types of data dependencies between tasks and schedule the tasks based on the data dependency status at runtime. The following data dependency types are available:
-
Producer-Consumer dependency
A dependency formed between the producer task of a data object of a specific version and a consumer task of the data object of the same version. It is also referred to as a read-after-write dependency.
-
Consumer-Producer dependency
A dependency formed between a consumer task of a data object of a specific version and the producer task of the data object of the next version. It is also referred to as a write-after-read dependency.
-
Producer-Producer dependency
A dependency formed between the producer task of a data object of a specific version and a producer task of the data object of the next version. It is also referred to as a write-after-write dependency.
Assume that the relationship between some tasks and data A is as follows:
task1(OUT A);
task2(IN A);
task3(IN A);
task4(OUT A);
task5(OUT A);
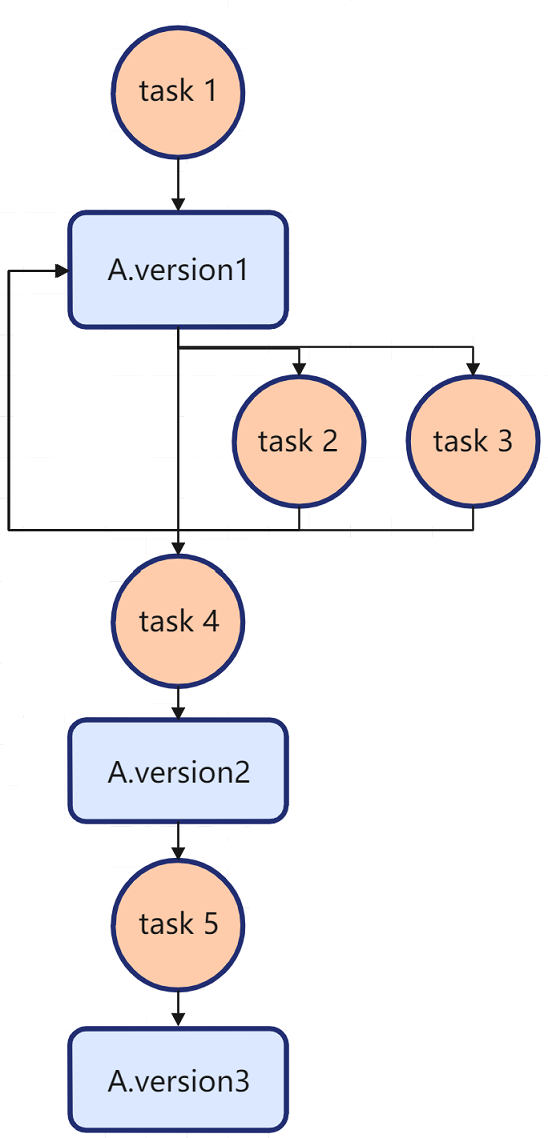
NOTE
For ease of description, circles are used to represent tasks and squares are used to represent data.
The following conclusions can be drawn:
- task1 and task2/task3 form a producer-consumer dependency. This means that task2/task3 can read data A only after task1 writes data A.
- task2/task3 and task4 form a consumer-producer dependency. This means that task4 can write data A only after task2/task3 reads data A.
- task 4 and task 5 form a producer-producer dependency. This means that task 5 can write data A only after task 4 writes data A.
Constraints
The thread_local variable is not supported.
The behavior of creating the thread_local variable in a task or transferring it between tasks is uncertain. The reason is that FFRT does not have the concept of thread. It only has the concept of task.
In C++ semantics, the thread_local variable can be compiled, but it is uncertain the thread on which the task that uses the variable is executed.
For non-worker threads in FFRT processes, the behavior of the thread_local variable is not affected by FFRT.
Similar problems occur for thread-bound features such as thread_idx, pthread_specific, recursive lock, thread priority, thread affinity, and recursive lock.
Do not use these features. If these features are required, use task local of FFRT instead.
Do not use FFRT in forked subprocesses.
Deploy FFRT in dynamic library mode.
Static library deployment may cause multi-instance problems. For example, when multiple .so files loaded by the same process use FFRT in static library mode, FFRT is instantiated into multiple copies, and their behavior is unknown.
After an FFRT object is initialized in the C code, you are responsible for setting the object to null or destroying the object.
To ensure high performance, the C APIs of FFRT do not use a flag to indicate the object destruction status. You need to release resources properly. Repeatedly destroying an object will cause undefined behavior.
Noncompliant example 1: Repeated calling of destroy() may cause unpredictable data damage.
#include "ffrt.h"
void abnormal_case_1()
{
ffrt_task_handle_t h = ffrt_submit_h([](){printf("Test task running...\n");}, NULL, NULL, NULL, NULL, NULL);
...
ffrt_task_handle_destroy(h);
ffrt_task_handle_destroy(h); // double free
}
Noncompliant example 2: A memory leak occurs if destroy() is not called.
#include "ffrt.h"
void abnormal_case_2()
{
ffrt_task_handle_t h = ffrt_submit_h([](){printf("Test task running...\n");}, NULL, NULL, NULL, NULL, NULL);
...
// Memory leak
}
Recommended example: Call destroy() only once; set the object to null if necessary.
#include "ffrt.h"
void normal_case()
{
ffrt_task_handle_t h = ffrt_submit_h([](){printf("Test task running...\n");}, NULL, NULL, NULL, NULL, NULL);
...
ffrt_task_handle_destroy(h);
h = nullptr; // if necessary
}
The number of input and output dependencies is limited.
For submit(), the total number of input dependencies and output dependencies of each task cannot exceed 8.
For submit_h(), the total number of input dependencies and output dependencies of each task cannot exceed 7.
When a parameter is used as both an input dependency and an output dependency, it is counted as one dependency. For example, if the input dependency is {&x} and the output dependency is also {&x}, then the number of dependencies is 1.
It is recommended that FFRT mutex be used in FFRT task context.
FFRT provides performance implementation similar to std::mutex. FFRT mutex can be called only inside an FFRT task. If it is called outside an FFRT task, undefined behavior may occur.
std::mutex may cause unexpected kernel mode trap when it fails to lock a mutex. FFRT mutex solves this problem and therefore provides better performance if used properly.
FFRT supports a maximum of eight worker threads. When eight tasks use std::mutex at the same time, deadlock occurs on all threads during coroutine switchover. Therefore, exercise caution when using std::mutex.