Function Flow Runtime Kit概述
简介
FFRT: Function Flow Runtime, 一种并发编程框架,提供以数据依赖的方式构建异步并发任务的能力;包括数据依赖管理、任务执行器、系统事件处理等。并采用基于协程的任务执行方式,可以提高任务并行度、提升线程利用率、降低系统线程总数;充分利用多核平台的计算资源,保证系统对所有资源的集约化管理。最终解决系统线程资源滥用问题,打造极致用户体验。
基本概念
Function Flow编程模型是一种基于任务和数据驱动的并发编程模型,允许开发者通过任务及其依赖关系描述的方式进行应用开发。FFRT(Function Flow Runtime)是支持Function Flow编程模型的软件运行时库,用于调度执行开发者基于Function Flow编程模型开发的应用。通过Function Flow编程模型和FFRT,开发者可专注于应用功能开发,由FFRT在运行时根据任务依赖状态和可用执行资源自动并发调度和执行任务。
两种编程模型对比
| 线程编程模型 | FFRT任务编程模型 | |
|---|---|---|
| 并行度挖掘方式 | 程序员通过创建多线程并把任务分配到每个线程中执行来挖掘运行时的并行度 | 程序员(编译器工具或语言特性配合)静态编程时将应用分解成任务及其数据依赖关系,运行时调度器分配任务到工作线程执行 |
| 谁负责线程创建 | 程序员负责创建线程,线程编程模型无法约束线程的创建,滥用可能造成系统中大量线程 | FFRT运行时负责工作线程池的创建和管理由调度器负责,程序员无法直接创建线程 |
| 负载均衡 | 程序员静态编程时将任务映射到线程,映射不合理或任务执行时间不确定造成线程负载不均 | FFRT运行时根据线程执行状态调度就绪任务到空闲线程执行,减轻了线程负载不均问题 |
| 调度开销 | 线程调度由内核态调度器完成,调度开销大 | FFRT运行时在用户态以协程方式调度执行,相比内核线程调度机制更为轻量,减小调度的开销,并可通过硬化调度卸载进一步减小调度开销 |
| 依赖表达 | 线程创建时即处于可执行状态,执行时与其他线程同步操作,增加线程切换 | FFRT运行时根据任务创建时显式表达的输入依赖和输出依赖关系判断任务可执行状态,当输入依赖不满足时,任务不被调度执行 |
Function Flow 任务编程模型
Function Flow编程模型允许开发者通过任务及其依赖关系描述的方式进行应用开发,其主要特性包括Task-Based 和 Data-Driven 。
Task-Based 特性
Task-Based 指在Function Flow编程模型中开发者以任务方式来组织应用程序表达,运行时以任务粒度执行调度。
任务定义为一种面向开发者的编程线索和面向运行时的执行对象,通常包含一组指令序列及其操作的数据上下文环境。
Function Flow编程模型中的任务包含以下主要特征:
- 任务之间可指定依赖关系,依赖关系通过
Data-Driven方式表达。 - 任务可支持嵌套,即任务在执行过程中可生成新的任务下发给运行时,形成父子任务关系。
- 多任务支持互同步操作,例如等待,锁,条件变量等。
注意
任务颗粒度影响应用执行性能,颗粒度过小增加调度开销,颗粒度过大降低并行度。Function Flow编程模型中任务的目标颗粒度最小为100us量级,开发者应注意合理控制任务颗粒度。
Data-Driven 特性
Data-Driven指任务之间的依赖关系通过数据依赖表达。
任务执行过程中对其关联的数据对象进行读写操作。在Function Flow编程模型中,数据对象表达抽象为数据签名,每个数据签名唯一对应一个数据对象。
数据依赖抽象为任务所操作的数据对象的数据签名列表,包括输入数据依赖in_deps和输出数据依赖out_deps。数据对象的签名出现在一个任务的in_deps中时,该任务称为数据对象的消费者任务,消费者任务执行不改变其输入数据对象的内容;数据对象的签名出现在任务的out_deps中时,该任务称为数据对象的生产者任务,生产者任务执行改变其输出数据对象的内容,从而生成该数据对象的一个新的版本。
一个数据对象可能存在多个版本,每个版本对应一个生产者任务和零个,一个或多个消费者任务,根据生产者任务和消费者任务的下发顺序定义数据对象的多个版本的顺序以及每个版本所对应的生产者和消费者任务。
数据依赖解除的任务进入就绪状态允许被调度执行,依赖解除状态指任务所有输入数据对象版本的生产者任务执行完成,且所有输出数据对象版本的所有消费者任务执行完成的状态。
通过上述Data-Driven的数据依赖表达,FFRT在运行时可动态构建任务之间的基于生产者/消费者的数据依赖关系并遵循任务数据依赖状态执行调度,包括:
-
Producer-Consumer 依赖
一个数据对象版本的生产者任务和该数据对象版本的消费者任务之间形成的依赖关系,也称为Read-after-Write依赖。
-
Consumer-Producer 依赖
一个数据对象版本的消费者任务和该数据对象的下一个版本的生产者任务之间形成的依赖关系,也称为Write-after-Read依赖。
-
Producer-Producer 依赖
一个数据对象版本的生产者任务和该数据对象的下一个版本的生产者任务之间形成的依赖关系,也称为Write-after-Write依赖。
例如,如果有这么一些任务,与数据A的关系表述为:
task1(OUT A);
task2(IN A);
task3(IN A);
task4(OUT A);
task5(OUT A);
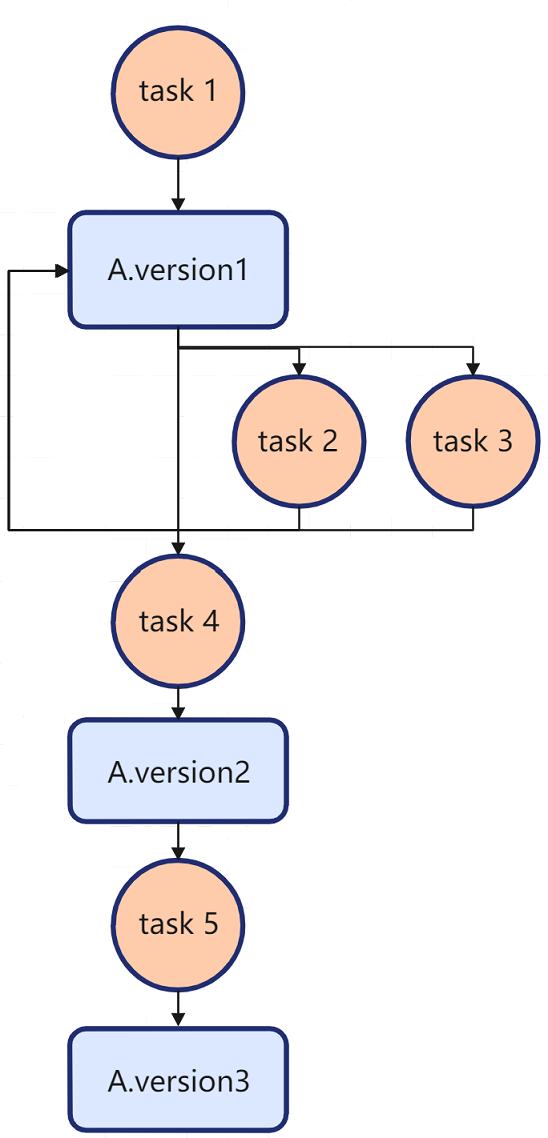
为表述方便,本文中的数据流图均以圆圈表示 Task,方块表示数据。
可以得出以下结论:
- task1 与task2/task3 构成Producer-Consumer 依赖,即:task2/task3 需要等到task1 写完A之后才能读A
- task2/task3 与task4 构成Consumer-Producer 依赖,即:task4 需要等到task2/task3 读完A之后才能写A
- task4 与task5 构成Producer-Producer 依赖,即:task5 需要等到task4 写完A之后才能写A
约束与限制
不支持thread_local变量
-
Task内部创建或Task间传递的thread_local变量的行为都是不确定的
-
原因在于FFRT在编程模型中已经没有thread的概念,只有task的概念
-
在C++的语义下,thread_local可以被正常编译,但是使用该thread_local变量的task在哪一个线程上执行时不确定的
-
对于使用了FFRT进程中的non-worker,thread_local的行为不受FFRT影响
类似的,与thread绑定的thread_idx/pthread_specific/递归锁/线程优先级/线程亲和性/递归锁具有相似的问题
建议
- 避免使用这些特性,如必须使用,使用FFRT的task local来替代
不支持用户在fork出的子进程内使用ffrt
以动态库方式部署FFRT
- 只能以动态库方式部署FFRT,静态库部署可能有多实例问题,例如:当多个被同一进程加载的so都以静态库的方式使用FFRT时,FFRT会被实例化成多份,其行为是未知的,这也不是FFRT设计的初衷
C API中初始化ffrt对象后,对象的置空与销毁由用户负责
- 为保证较高的性能,ffrt的C API中内部不包含对对象的销毁状态的标记,用户需要合理地进行资源的释放,重复调用各个对象的destroy操作,其结果是未定义的
- 错误示例1,重复调用destroy可能造成不可预知的数据损坏
#include "ffrt.h"
void abnormal_case_1()
{
ffrt_task_handle_t h = ffrt_submit_h([](){printf("Test task running...\n");}, NULL, NULL, NULL, NULL, NULL);
...
ffrt_task_handle_destroy(h);
ffrt_task_handle_destroy(h); // double free
}
- 错误示例2,未调用destroy会造成内存泄漏
#include "ffrt.h"
void abnormal_case_2()
{
ffrt_task_handle_t h = ffrt_submit_h([](){printf("Test task running...\n");}, NULL, NULL, NULL, NULL, NULL);
...
// memory leak
}
- 建议示例,仅调用一次destroy,如有必要可进行置空
#include "ffrt.h"
void normal_case()
{
ffrt_task_handle_t h = ffrt_submit_h([](){printf("Test task running...\n");}, NULL, NULL, NULL, NULL, NULL);
...
ffrt_task_handle_destroy(h);
h = nullptr; // if necessary
}
输入输出依赖数量的限制
- 使用submit接口进行任务提交时,每个任务的输入依赖和输出依赖的数量之和不能超过8个。
- 使用submit_h接口进行任务提交时,每个任务的输入依赖和输出依赖的数量之和不能超过7个。
- 参数既作为输入依赖又作为输出依赖的时候,统计依赖数量时只统计一次,如输入依赖是{&x},输出依赖也是{&x},实际依赖的数量是1。
建议ffrt任务上下文使用ffrt锁
- FFRT提供了类似的std::mutex的性能实现,只能在FFRT task内部调用,在FFRT task外部调用存在未定义的行为。
- std::mutex在抢不到锁时会陷入内核的问题,ffrt锁在使用得当的条件下会有更好的性能。
- FFRT最多worker数量为8,当同时8个任务都使用std锁后进行协程切换,会出现线程全部死锁问题,慎用std锁。